Intelligent Document Processing (IDP)
Extract data from any document with guaranteed quality. Leverage the latest AI models and super.AI Data Processing Crowd for human-in-the-loop (HITL) review.
Trusted By Enterprises In Logistics, Shipping, Financial Services, And Technology Worldwide
Go Beyond Data Labeling
Our ready-to-deploy resource pool goes beyond data labeling to provide post-processing and exception handling. Further reduce the burden on teams building and maintaining AI applications with the super.AI Data Processing Crowd.
On-demand Scaling
Scale resources up or down to meet evolving business objectives and SLAs.
Any Data Type
Leverage workers capable of processing any data type, including documents, images, videos, text, and audio.
Quality Control
Over 150 built-in quality control mechanisms automatically assess data processing output.
Gamification
Keep human workers engaged and operating at the highest level with task gamification.
Enterprise-grade Security
Enterprise-grade security is built into every aspect of how data is processed and handled by our Data Processing Crowd.
Localized Processing
Satisfy GDPR and other data privacy regulatory requirements with localized data processing.
Why choose the super.AI Data Processing Crowd?
super.AI's Data Processing Crowd offers a number of advantages over standard solutions for human-in-the-loop. The chart below summarizes key differences between our offering and the competition.
| super.AI HITL | Standard HITL | |
|---|---|---|
| Validation Queues | ||
| Role-based Access Control (RBAC) | ||
| Escalation Rules | Limited | |
| Skills Qualification | ||
| Task-specific Processing Instructions | ||
| On-demand Resource Scaling | ||
| Task Gamification | ||
| Quality Assurance Mechanisms | 150+ | |
| Pricing model | Pay-Per-Use | Pay per Headcount |
How Does the super.AI Data Processing Crowd Work?
Here’s how we tap the right crowd for the job and guarantee results.
Skills Qualification
Workers must pass general skills tests that evaluate abilities such as reading comprehension, adherence to instructions, and more. Most importantly, tests that use your specific data are administered during qualification.
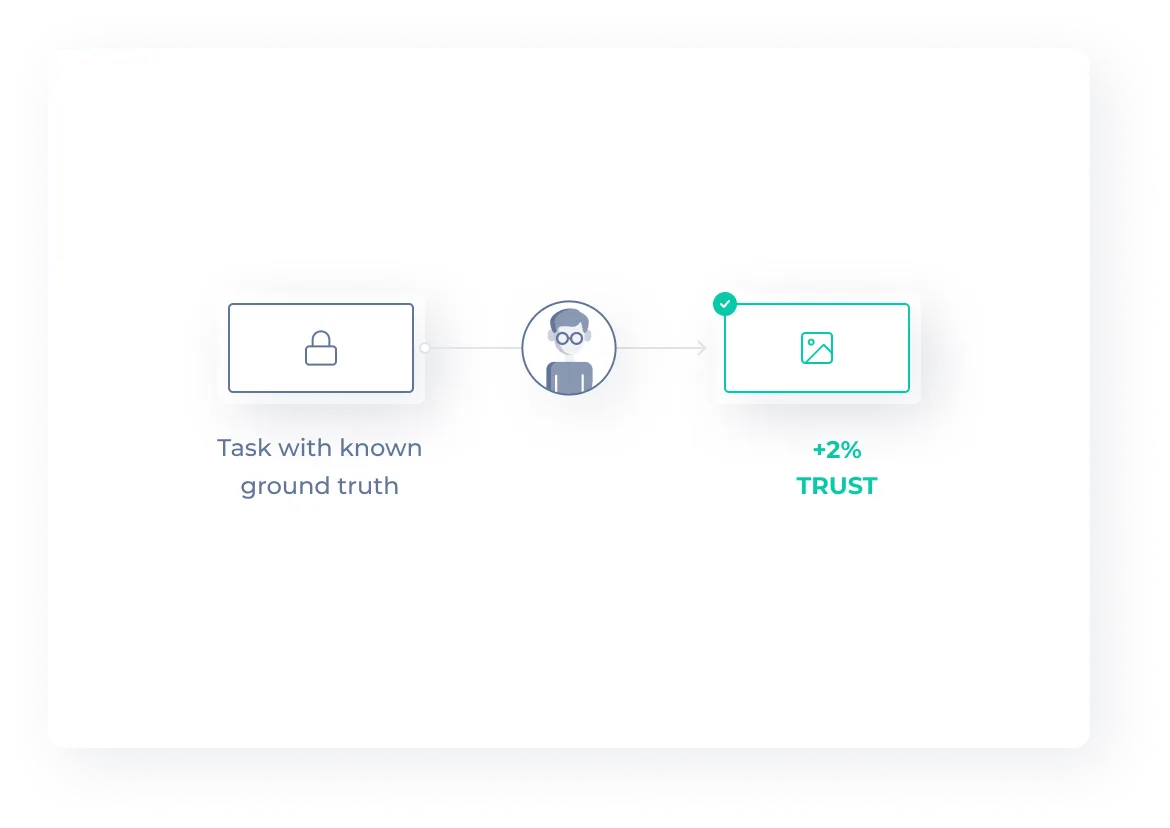
Continuous QA
Tasks with known answers (ground truth) are sent to workers at random to ensure output quality is consistent. Inconsistent workers are checked more frequently, while consistent workers are checked less frequently.
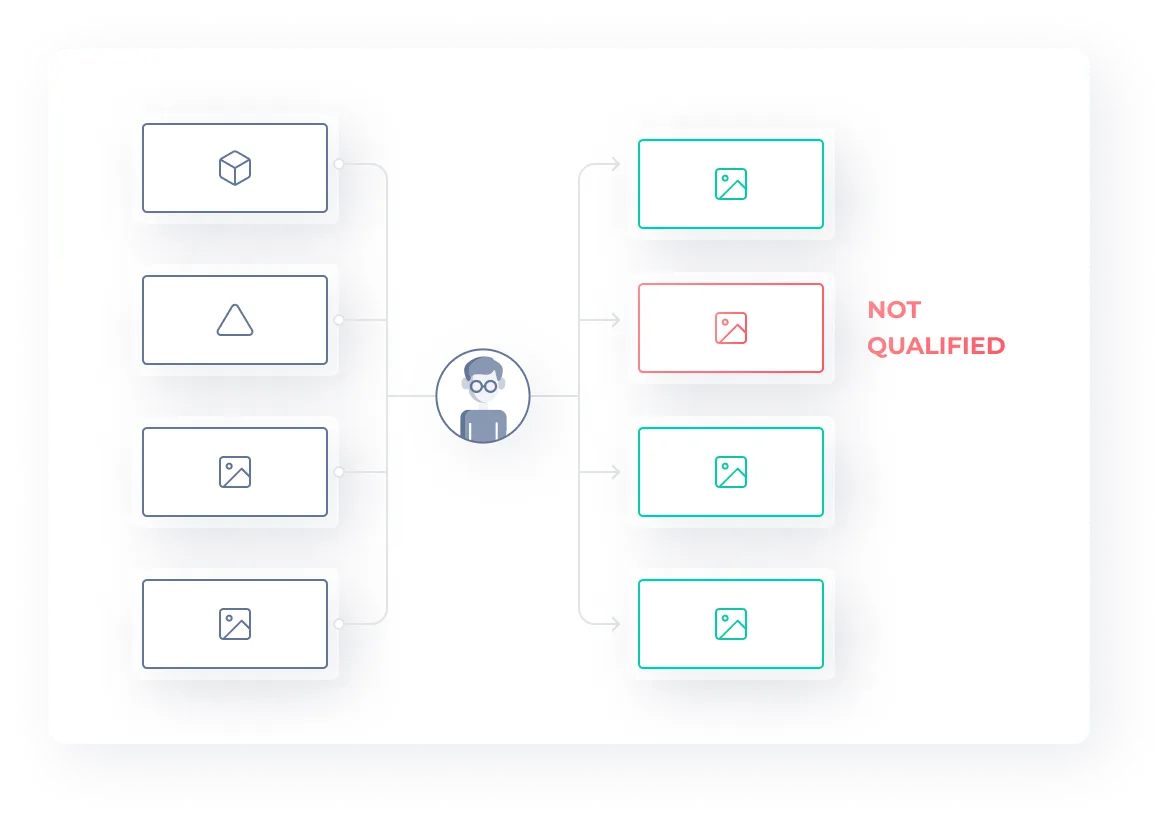
Consistency Scoring
Permutations of the same tasks are sent to workers to identify temporary drops in performance due to fatigue or distraction.
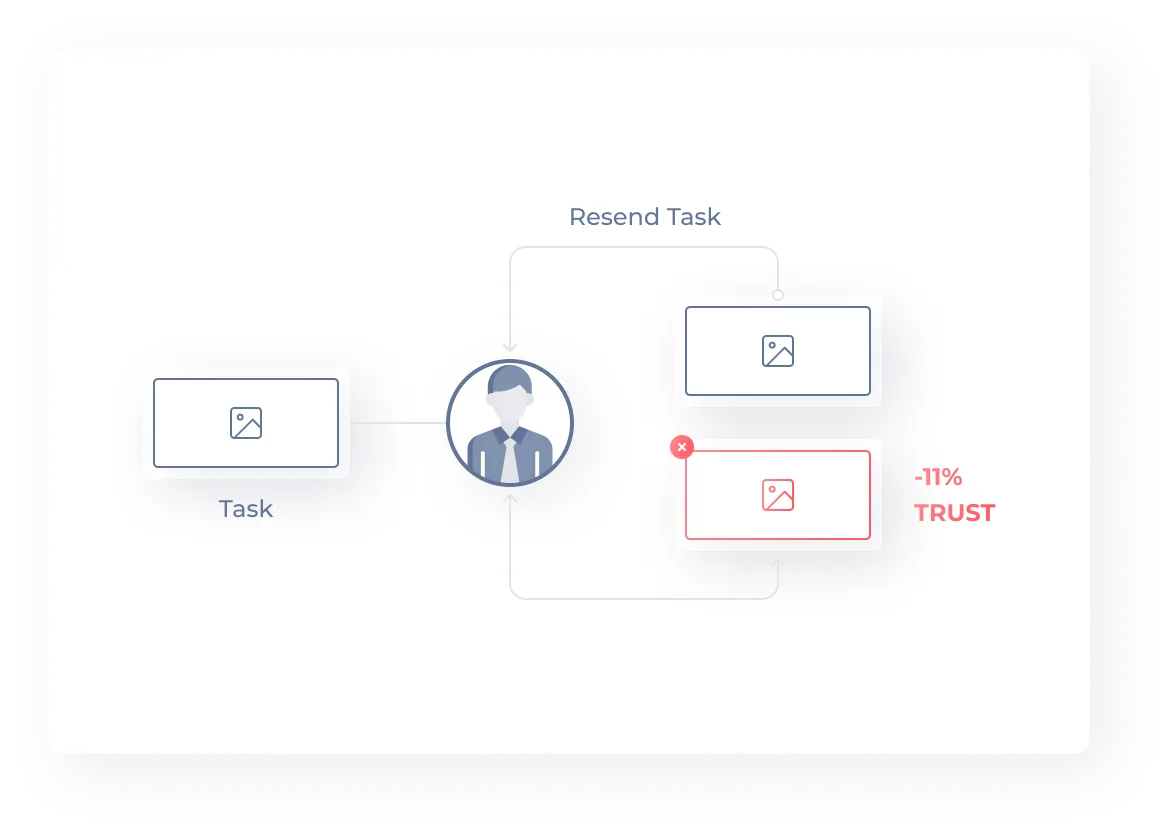
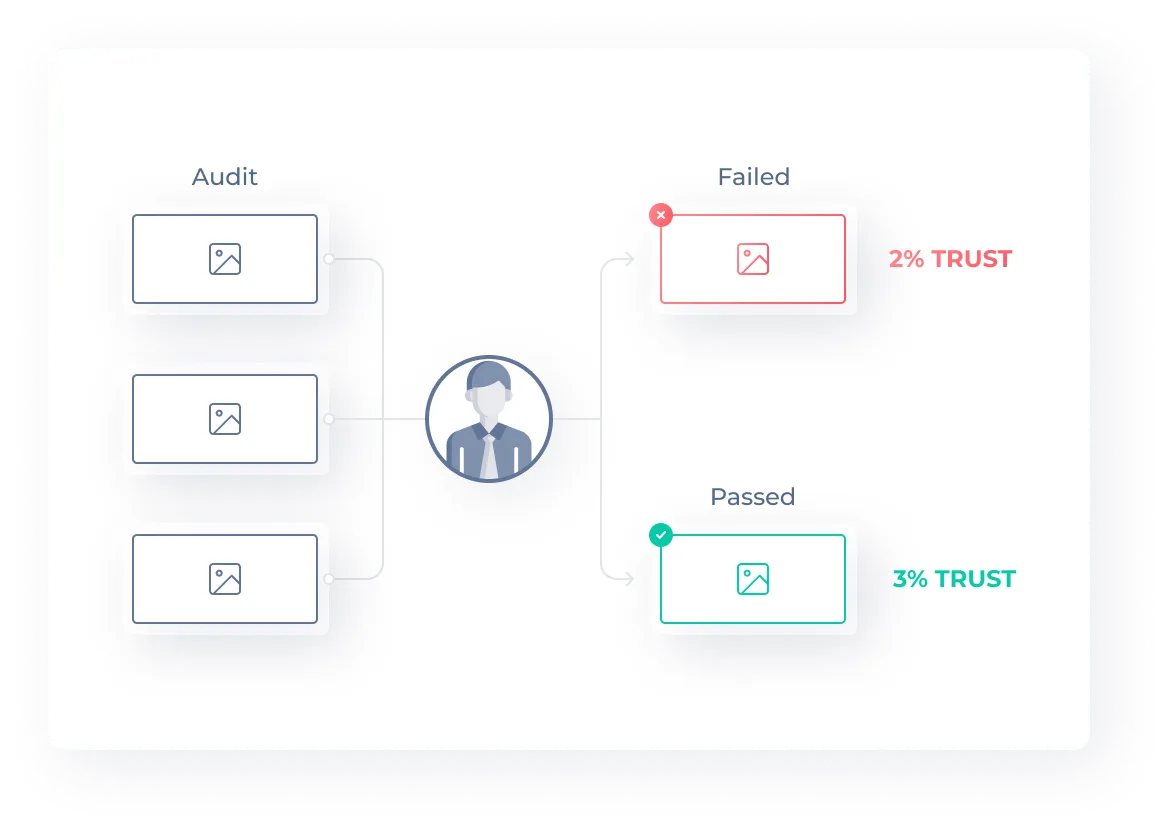
Internal Audit Team
If an anomaly is detected during task processing, an internal audit team is notified. Experts in writing and debugging instructions help resolve any issues.
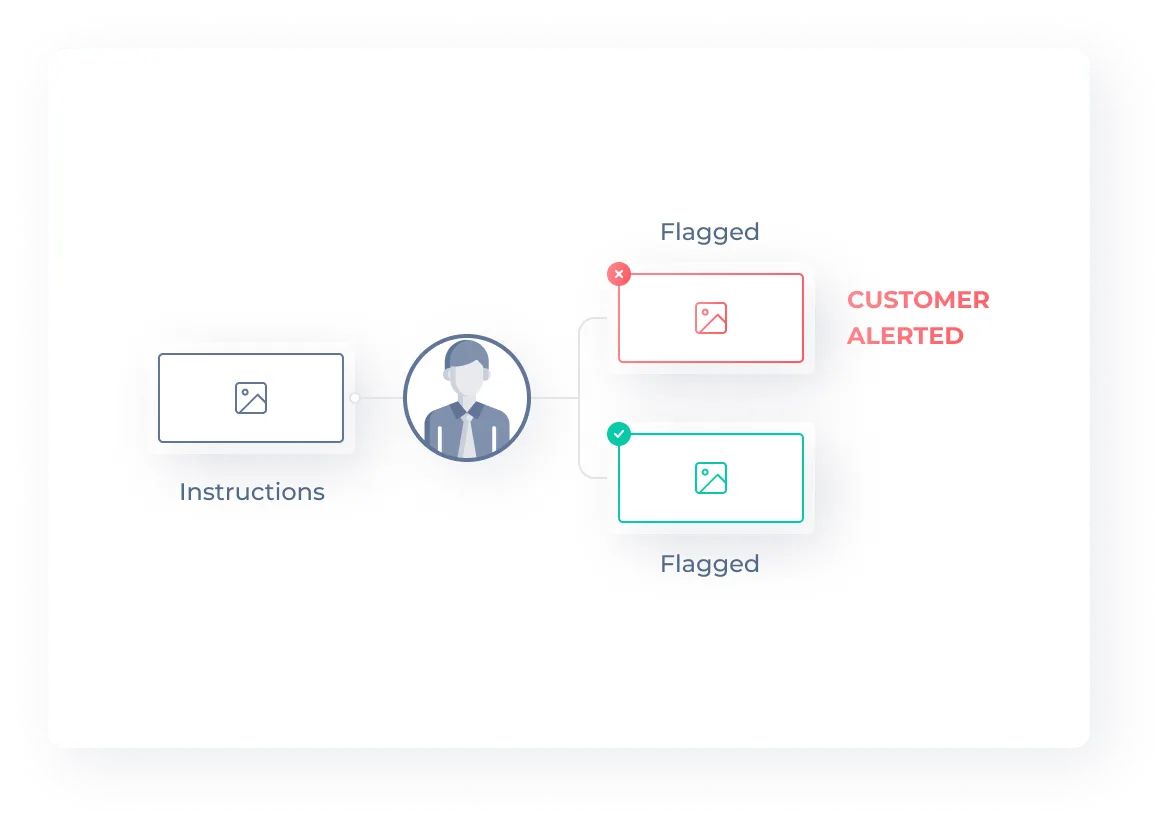
Expert Review
Tasks that pass through the quality control pipeline without reaching a user-defined accuracy threshold can be routed to experts (in-house or third-party) for review. Our platform is designed to minimize the use of an expert review panel as much as possible.
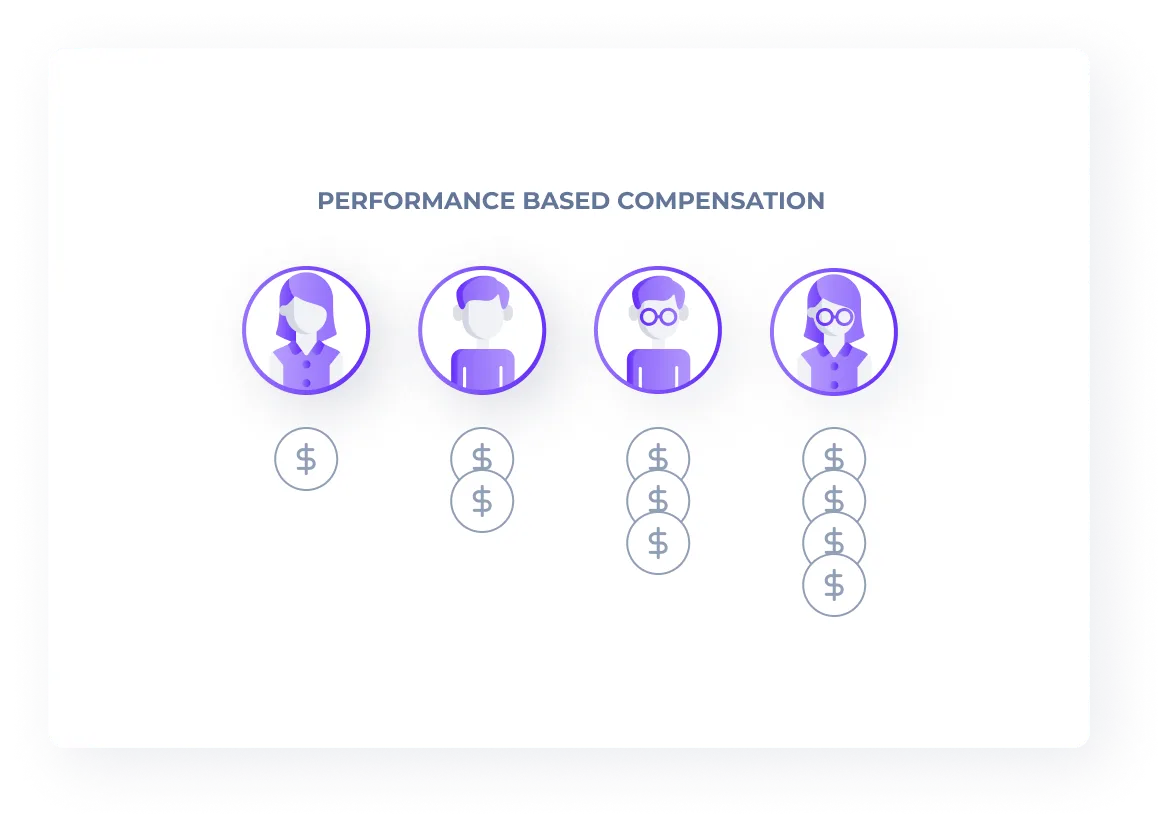
Performance-based Compensation
Workers are compensated based on the value they provide to you. High-performing workers receive more responsibility and compensation over time — creating an incentive to resolve tasks accurately and develop their skills.
Intelligent Document Processing (IDP)
Automate information extraction from any business document with guaranteed quality using next-generation AI and Data Processing Crowd.