By super.AI

They say data is more valuable than ever. And businesses are generating astronomical amounts of data. So why aren’t we all rich by now?
Yes, data has value. But before you can get started with data monetization, or leveraging data for digital transformation, there’s this stuff called unstructured data. Unstructured data sits at the very foundation of the insights value chain that determines how well you can capitalize on your data.
Here’s the thing: Most business information is unstructured, hidden in plain sight within everyday things like emails, images, PDFs, videos and call transcripts, and lots more. Gartner estimates 80% of all data is unstructured, and growing.
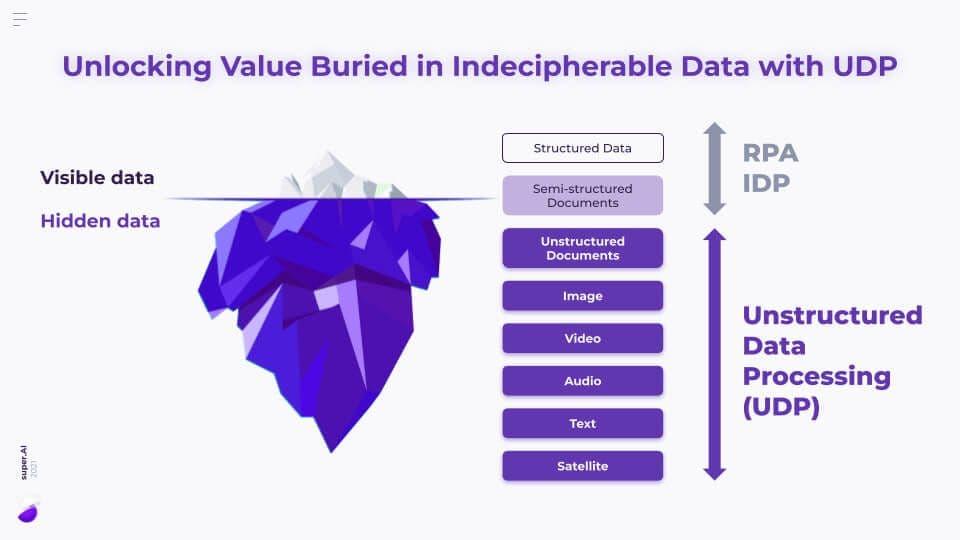
The implication for enterprises of all sizes is that 80% or more of your data is locked away in this hidden unstructured format.
And there are things you can do to process this and automate that, but most data remains inaccessible—which is why we’ve built unstructured data processing (UDP) tools that can handle most of the data in existence. And if you think 80% is a lot, it’s going to be 99.9% of data very soon.
-Brad Cordova, CEO, Super.AI
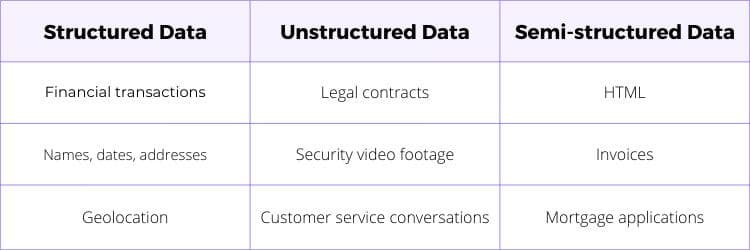
Data is characterized by its level of structure; that is, how easily it can be exported/extracted, organized, and stored.
Highly structured data, like payroll records or customer contact info, is straightforward to use and analyze. Unfortunately, only about 10% of data is ready and waiting in structured format.
Unstructured data is everything else. It can be helpful to further subdivide unstructured data into semi-structured data as well. Semi-structured data, like invoices or mortgage application forms, includes tags or semantic markers that may provide structural guideposts.
All types of data are growing, but unstructured data is looking at the others in the rearview mirror, growing at a breakneck pace between 55%-65% per year.
The information age got its name for a reason. For nearly 50 years, companies have collected growing amounts of information and struggled to store and manage it all. The volume and velocity at which unstructured data is generated makes it seem like a blob-villain from sci-fi movies. So it’s no surprise that today most enterprises find unstructured data a burden rather than a strategic asset.
Consider email. At first glance, a customer service inbox with 150,000 emails from customers may seem like not much more than a restaurant receipt spike, where filled order slips go to die.
But that stack of emails has potential. What if you mine it for insights about your customers, the questions they’re asking, and how satisfied they were with the resolution? And what if you use those newfound insights to train an intelligent system to categorize incoming customer inquiries and respond with the best-match answer, or direct them to the right customer support team? Those 150,000 emails (and all future customer inquiry data) have transformed into a business asset.
“What ifs” about data are tempting. Analogies like “data is the new oil” seem to suggest a get-rich-quick shortcut is right under foot. But there always seems to be a glaring omission: just how do you turn unstructured data into quality information?
The answer to that question has in many ways been data science’s dirty secret. Not long ago, research found that data scientists spend 80% of their time preparing data, leaving just 20% to actually work on machine learning models. What goes into all of that data preparation? Other than processing all of the data by hand, common approaches to enrich and structure data include:
Even at a glance, it’s clear that all of these approaches suffer from unreliable output accuracy, high costs, or both. And all of these approaches fail to capitalize on advances in AI technology that enable unstructured data processing (UDP) to be automated.
Unstructured data processing (UDP) uses AI to convert unstructured and semi-structured data into high-quality structured information. Unlike weak supervision data, UDP delivers high-accuracy output by combining AI, bot, and human intelligence in an AI “assembly line” approach—an approach that allows UDP solutions to offer guaranteed data quality.
UDP is designed to process data rapidly from day one and learn quickly, increasing the speed and level of automation over time. That means the percentage of unstructured data that is routed through automated, self-improving, AI models keeps increasing, resulting in near-perfect data accuracy, delivered at high speed.
Legacy data capture software is primarily based on optical character recognition (OCR). This technology works by extracting data using templates, which means only structured information sources can be processed. Even though OCR only works for structured data, the extracted information still needs to be validated before you can reliably use it.
Intelligent document processing (IDP) represents a major evolution for extracting information from documents. IDP is not template based, instead leveraging machine learning models to train up and adjust to source data and handle document complexity, such as semi-structured documents like contracts and emails.
Unstructured data processing significantly expands on the scope of IDP to encompass any data source. IDP is limited to documents; UDP handles documents, images, video, audio, text, etc. Using AI, UDP self-validates captured information which means data can be sent directly into action, enabling straight through processing (STP).
But there’s more. Extraction is one aspect of UDP. Automatically processing unstructured data with AI offers other valuable capabilities including PII redaction, data classification, and even answering natural language queries about the data set.
Perhaps most important, UDP is built with non-technical business users in mind. For enterprises looking to unlock the value of business data this should come as very good news. Data scientists continue to be in short supply, with the volume of job postings for data scientists recently outstripping job searches for those roles by 300%.
UDP is built on the premise that accessing unstructured business information should be easy. In the context of our data example before, UDP puts the ability to glean insights from customer emails to automate and improve the customer experience within reach of the customer support team itself.
In the quest for enterprise-wide digital transformation, UDP is an essential tool to empower employees to harness data, extract value from newly accessible information and insights, and bring it to bear on the problems they know intimately within their teams, departments, and beyond.
The bottom line? Unstructured data processing enables you to get exactly the information you need from any data in any format, on repeat, enabling business process transformation to take flight.
Intelligent unstructured data processing is the latest evolution of data entry automation, able to capture unstructured data from any source, classify, categorize, and extract or redact relevant information, and then validate the data. UDP processes complex sources of information by applying AI models and AI technologies such as natural language processing (NLP), and machine learning (ML).
The foundation of UDP is the ability to decompose the complex problem of processing unstructured data into a reusable, automated, data processing workflow. Breaking UDP down into process steps shows how simple and straightforward it can be to apply UDP to your unstructured data.
With most business data trapped in inaccessible formats, quickly and easily transforming unstructured and semi-structured information into usable data is the gateway to capitalizing on the value of data and accelerating nearly every aspect of digital transformation.
AI-automated unstructured data processing (UDP) delivers critical benefits for enterprises on the journey of transformation, including:
Unstructured data processing tools are completely non-invasive, integration-friendly, and are widely applicable across industries and business functions.
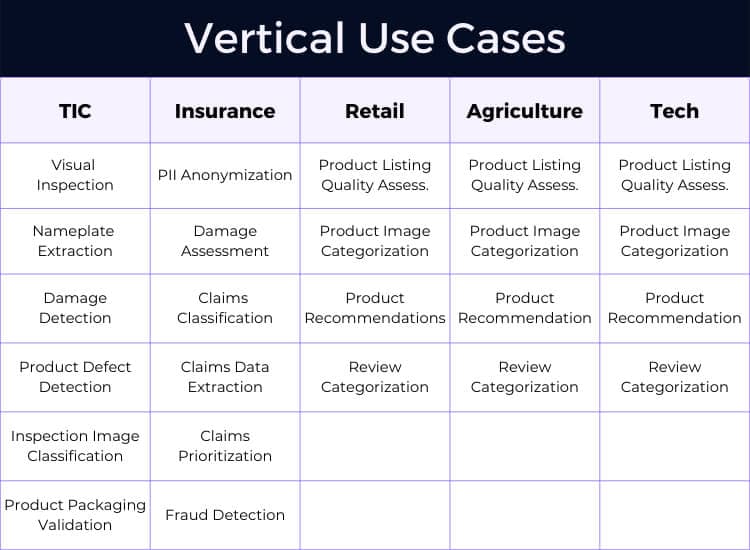
Common use cases for UDP across industries include:
Within specific industries, UDP goes even deeper to address industry-specific data processing needs, such as PII anonymization and claims data extraction in Insurance, inspection image classification and damage detection in Testing, Inspection, and Certification (TIC), and product listing quality assessment in retail.
Digital transformation hinges on data availability; UDP transforms all data into process-ready information. By surfacing and enhancing unstructured “dark data”, unstructured data processing is part of the digital enterprise foundation, essential to automation and business process transformation.
The best part is how accessible UDP is today to the average business, without needing data science expertise. Interested in trying it out or learning more? Here are some quick links to get started:


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.