By super.AI

Global finance runs on data. Although the core documents of finance deal with numbers in credit, debit, profit, and loss and are largely structured, the supporting (yet still very much essential) documents are highly variable and often unstructured. This lack of structure arises from the variety of sources the documents come from, the range of operations that rely on financial data, and the variations in the type of data they entail. For example:
The ambiguity and variety found in document stores, both in terms of content and type, leads to challenges in harvesting meaningful information from them. Thus, many financial institutions have dormant repositories of documents containing unstructured or “dark data” due to a lack of tools and strategies for data extraction, analysis, and management.
Data from unstructured documents can provide valuable information that can help companies derive actionable insights, mitigate risk, enhance user engagement, and streamline compliance. Manual extraction and interpretation of unstructured data is time-consuming, resource-intensive, and error-prone. Additionally, ignoring unstructured data can lead to knowledge gaps and missed opportunities.
Effectively handling, managing and integrating structured, unstructured and semi-structured documents and data requires more than manual labor and legacy Optical Character Recognition (OCR) solutions have to offer. Most existing OCR, which power first-generation Intelligent Document Processing (IDP) solutions, are quite effective when it comes to processing structured documents. However, these tools are dependent on templates or proprietary machine learning (ML) models that are too inflexible (and unintelligent) to accurately process unstructured documents.
More modern IDP solutions that are built on Unstructured Data Processing (UDP) platforms are capable of handling not only unstructured documents, but any unstructured data type (e.g., audio, images, and video). Additionally, these solutions also often include robust human-in-the-loop (HITL) functionality that seamlessly integrates human workers for model training and quality assurance.
Data from credit card and bank statements must be extracted for various purposes by both customers and financial institutions. In the simplest case, any loan or mortgage application requires that the customer provide bank statements and credit card statements for assessment of credit worthiness. These credit card statements and bank statements are of different formats depending on the source institution.
A typical credit card or bank statement is a consolidated report of all transactions conducted by the credit card or account holder in a specific time period. All credit card and/or bank statements contain the following information, in different orders and formats
Although statements differ in format between institutions, a well-organized statement is physically divided into three sections—one containing personal customer information, one containing account details, and one documenting the transactions that occurred during the statement period (typically presented in tables).
Manual extraction of data from credit card and bank statements is tedious and legacy OCR cannot deal with the unstructured nature of these statements. Modern IDP solutions offer the best option for quickly extracting, organizing, and processing statements. Credit reporting also requires rigorous security checks and IDP solutions can help recognize, categorize and compare credit card and bank statements with security check documents such as IDs, proof of income, digital signatures, and more.
The filing of tax returns and even tax provisioning—the estimation of tax that an enterprise is required to pay in a year—involves abundant data, both structured, such as those stored in enterprise resource planning (ERP) systems or unstructured data in the form of physical bills and invoices, amendments, contracts, memos and strategic, business, and legal decisions. Even apparently semi-structured data such as spreadsheet information are in truth, unstructured, due to the absence of embedded controls.
The volume of data, constantly updated tax rules, and deadline-oriented nature of the work complicate processing of unstructured data in taxation and tax provisioning activities. While the math behind tax calculation is often simple arithmetic, the integration of structured and unstructured data from finance and tax repositories complicates the process. Like all finance matters, tax calculation and provisioning must be error-free because inaccurate estimates could lead to financial loss, return errors, and reconciliation complications.
IDP solutions can intelligently extract data from W2 forms, pay stubs, receipts, invoices, and bank statements and categorize them. When combined with tax report forms, they can populate the various fields and also calculate the tax estimates, filings, and returns.
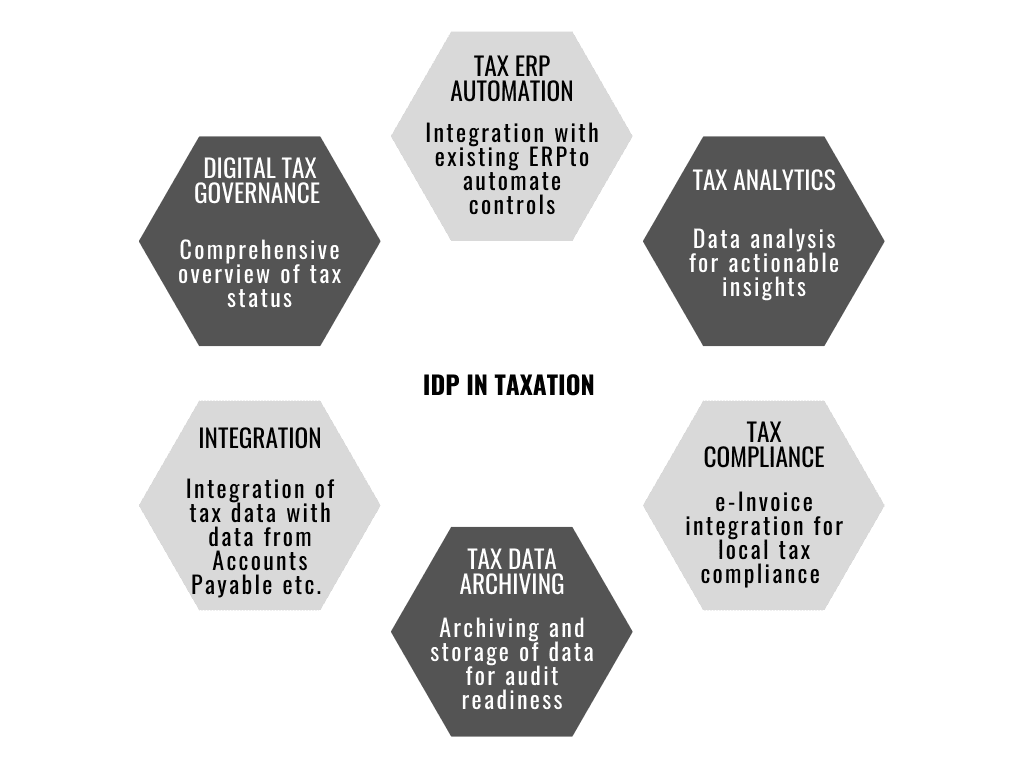
Intelligent Document Processing (IDP) in taxation.
A complete understanding of the provisions of loan agreements is critical to prevent mismanagement of funds, defaulting, and poor customer relationships. Poor data management can result in unwanted termination of loan contracts, legal action against breach, missing important deadlines and dates, regulatory fines, and ambiguity in the payment details.
The first step of loan agreement management is the digital categorization of data from the agreement. The use of IDP elements like Natural language Processing (NLP) and ML-based data extraction from agreements can encompass data pre-processing and automated extraction of meaningful data from the loan arrangement, to be stored in a digital repository for follow up actions and archiving. IDPs can be provided with intelligent clause detection functionalities that can enable contract management entities to easily access pertinent information such as the loanee details and financial clauses within the loan-provider’s pre-approved clause library.
IDP software can enable understanding of keywords specific to loan agreements, including recognizing descriptions of dates (“after fifteen business days”) and amounts (“equal to five percent (5%) of the loaned amount,” etc.). They can find semantic similarities and can identify provisions and clauses, with adequate training.
A deed of trust is an alternative to a mortgage and is used to obtain loans for immovable property like a plot of land or a house. The difference between a mortgage and a trust deed is that in the former, there are only two parties involved—the borrower and the lender—while in the trust deed, there is one other intermediary person—a neutral trustee. The borrower and lender are referred to as the trustor and the beneficiary, respectively. The trustee can be an individual or a company on a deed of trust, the legal title of the property is transferred to the trustee from the buyer until the borrower pays off the loan.

Example deed of trust inside the super.AI platform.
A deed of trust typically contains the following data:
IDP tools can extract all of the above data in an intelligent manner through the use of AI tools such as neural networks, decision trees, and rule learning techniques. A full end-to-end IDP system for the extraction and management of trust deed would use computer vision-based document analysis tools and information extraction tools that leverage ML-enhanced OCR.
Personal IDs such as passports, driver’s licenses, and national ID cards are presented by individuals to open bank accounts, purchase airline tickets, obtain travel visas, and apply for jobs/academic programs. Sometimes the original ID is presented to the asking authority, and sometimes photocopies are provided. ID images are also often scanned and emailed or faxed to recipients.
The information in the ID is usually entered into a system. The manual entry of ID is plagued by errors and inefficiencies that are expensive in terms of both time and monty. Legacy OCR data capture solutions are also of limited use because they cannot work with custom data.
Furthermore, IDs that are faxed or emailed as images are often of poor resolution, and of various sizes, shapes, and orientations. Finally, IDs may have multiple languages, and OCR cannot capture the nuances of languages, or even multiple fonts, in some cases. Neither can it discern front matter from background text such as watermarks. Considerable pre-and post-processing operations become necessary, which adds to both time delays and cost inefficiencies.
IDP tools can automate ID recognition processes in that they can learn from existing data to provide accuracy of data capture. IDP software can also identify orientation of images, and can differentiate between front text and watermarks. It can extract specific pages of interest from multiple pages of ID documents like passport. IDP systems are usually integrated with a backend database, which makes storage and retrieval of data easier.
Mortgage applications are paperwork-intensive and involve multiple file formats, templates, and document types. The application includes numerous supporting documents, including income verification documents, identity verification documents, loan application documents, etc., each of which is in a different format and may be unstructured digital data or hardcopies. Home and building mortgage applications, in particular, use significant amounts of unstructured data; the application is associated with an appraisal of the building or house, which continues to be largely narrative.
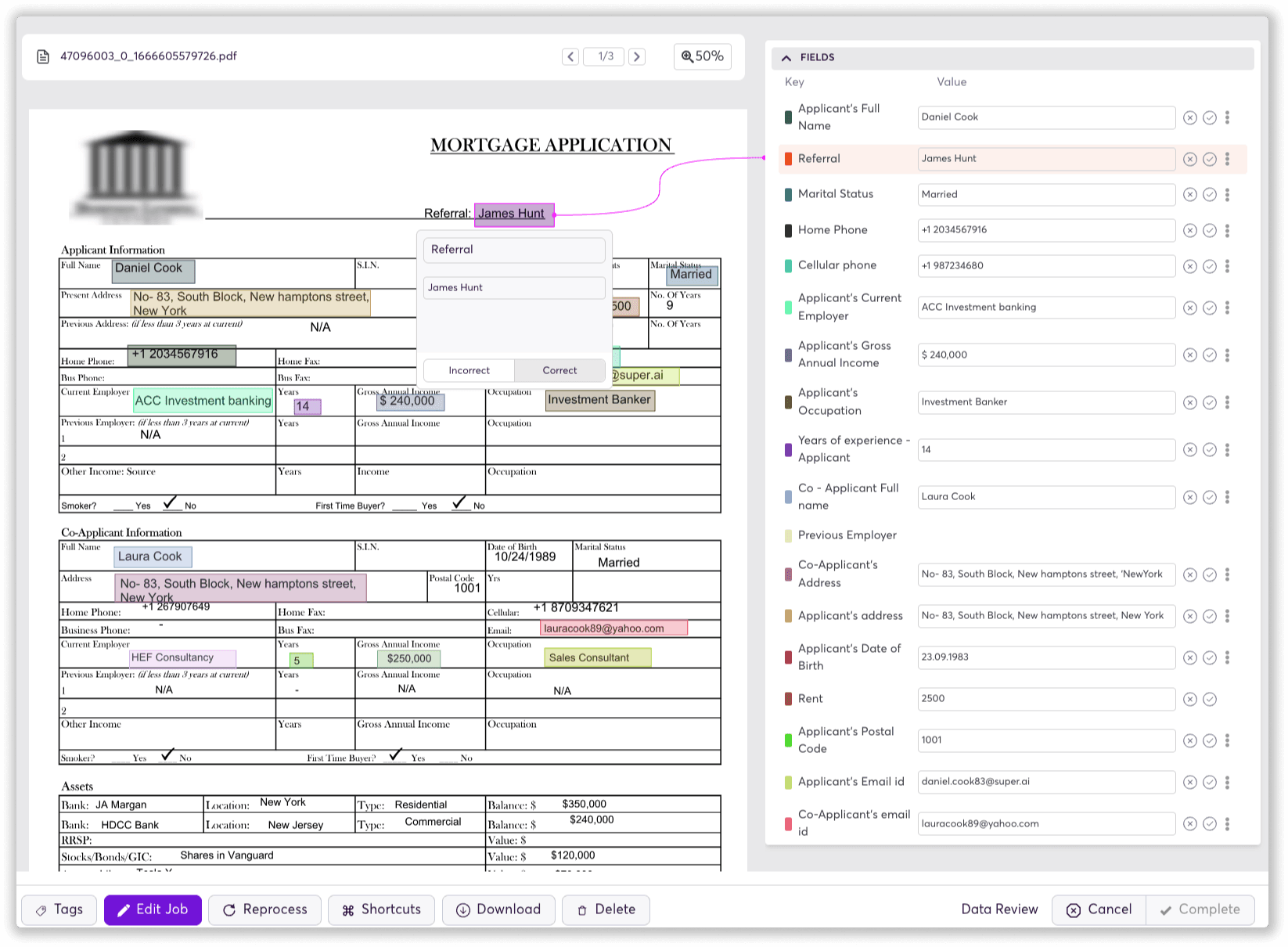
Example mortgage application inside the super.AI platform.
IDP can efficiently process mortgage underwriting by extracting useful data from even narrative-style documents to input into the credit evaluation system.McKinsey reports that mortgage application approval in the US takes an average of 37 days, of which 14-21 percent are spent on the manual processing of the application documents.
A lease is a legal agreement between a home/building owner and the renter and dictates the details of the lease of the house/building such as the period of lease, the cost of leasing, the payment methods, rules and regulations of use, and legal fine-print associated with the leasing process. A lease document often involves several complex terms that have specific and often quantifiable meanings and sometimes subjective language, which makes it a highly unstructured document.
Another interesting aspect of the lease agreement is that it is full of ‘dependencies’, i.e., various fields in the lease agreement are related to one another. For example, the leasing period may be related to the lease amount - so changing one can cause changes in the other. Conventional OCR systems cannot track and recognize dependencies.
IDC systems can capture pertinent data from leases and the AI tools in the backend can auto-process the in a way that mimics the human mind, thereby recognising dependencies. They can categorize data into contextual categories depending on the level of training and instructions provided by the end-user. IDCs can completely eliminate errors in data entry seen in Manual or OCR processes.
Many financial institutions are customer-centric enterprises. With increasing digital communication with the customer, information from feedback and survey forms must also become digital and intelligently categorized and classified to enhance customer experience and process improvements. All types of feedback, be them structured data such as information filled out in online forms, or unstructured such as comments, complaints, and posts must be coherently structured, organized, defined, validated, and used for meaningful engagement with existing and potential customers.
IIDP solutions provide a seamless platform that allows full and controlled access to relevant data culled from feedback and survey engines. IDP solutions go beyond merely digitizing feedback data but also include analytics functionalities that use the data to drive critical business processes and transactions, store audit, transaction or communication trails to both customer and the financial company, and prevent customer dissatisfaction in business processes.
Payslips are often required for many financial transactions such as loan applications, mortgage agreements, lease agreements, etc. Payslips contain information such as net salary, gross salary, bank account details, names and addresses of the employer and employee, employee ID, salary amount, salary period, rate of pay, tax withheld etc. Different applications require all or some of these details for validation purposes. Different payslips have different formats, which makes legacy OCR systems inefficient for data abstraction. Pay slip data are also often presented in a tabular format.
IDP systems can perform contextual extraction of data from payslips, depending upon the data needs of the target organization. It can also extract text from images, scanned photographs, and faxed documents, which makes it both time- and cost-effective.
The accounts payable and accounts receivable processes are perhaps the best to benefit from IDP systems for the digitization and intelligent processing of complex invoices. As with most documents, invoices come in a variety of formats, types and styles. Conventional processing of invoices involves the basic steps of identifying the relevant data fields, then comparing them (matching) with related documents such as PO and delivery receipts.
The use of IDP in invoice processing can reduce operational costs by 80% for enterprises, process payments ten times faster, perform automated 3-way match between PO, invoice and receiving reports, detect and handle exceptions and avoid risks of theft, fraud, maverick spends and other inefficiencies that could crop up in the manual process.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.