By Manish Rai

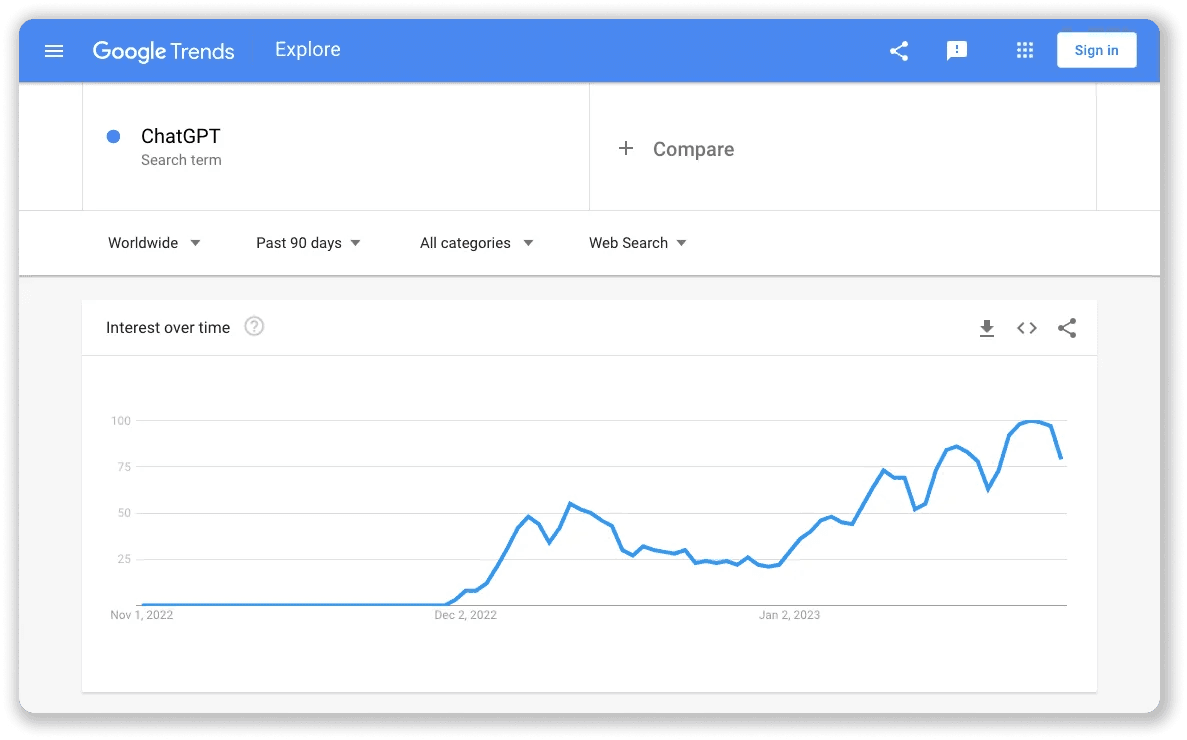
To say that ChatGPT has been trending recently would be a gross understatement. The popular Large Language Model (LLM), optimized for conversational dialogue, attracted more than 1 million users in less than a week, courted a $10 billion investment from Microsoft, caused Google and educators to panic (for different reasons), and inspired countless think pieces about AI taking over everything from marketing to therapy.
ChatGPT is an AI Swiss Army Knife that has something for everyone: it has been used to write essays, blogs, thank-you notes, limericks, and condolence messages; to answer questions on every subject, from quantum physics to the meaning of life; and even to write code. Despite its popularity and utility, ChatGPT also has detractors that have correctly pointed out its limitations— the most concerning of which might be its tendency to make stuff up.
As an artificial intelligence (AI) startup, we at super.AI understand ChatGPT’s limitations better than most. But we also have a more clear-eyed view of its potential. After spending some time playing around with the model, we started wondering how this next-generation LLM (or another like it) could be applied to the Intelligent Document Processing (IDP) and Unstructured Data Processing (UDP) markets.
We see LLMs helping IDP/UDP solutions in the following three areas:
Let’s take a closer look at the specific benefits LLMs can offer in each area.
One of the biggest challenges for IDP solutions is dealing with semi-structured and unstructured data found across document types and within documents of the same type. Consider invoices, where labels for invoice numbers, shipping and receiving addresses, and line items differ. Even with the best fuzzy matching and ML models, automated document processing solutions struggle to extract data from ~20-40% of invoices accurately.
Although we haven’t seen any research on closing this gap with LLMs, our intuition tells us this technology can help bring automation closer to human-level processing for semi-structured and unstructured data. In this case, the text extracted by OCRs would be used to train a Large Language Model, which would then be queried for desired key/value pairs.
Imagine if you could query a contract archive in natural language and be presented with the exact paragraph from the customer contract in question. Or if you could simply tell a system to summarize, translate, or even create new documents for you using a simple chat like user interface (UI). That is the promise of LLMs in simplifying the search and analysis experience for critical business documents. Each document is converted to machine-readable text using OCR, and the extracted information is used to train a LLM. This approach can deliver a ChatGPT-esque UI for querying and analyzing critical business information, allowing users to ask questions and issue commands such as:
Unified AI platforms like super.AI are designed to enable business users to process unstructured data such as documents, images, videos, and more. Today, the super.AI platform allows users to leverage existing AI applications built by our team or create their own quickly using our SDK. Within the SDK, users create custom AI apps called “data programs” that require them to:
Though this is much simpler than creating an AI application from scratch in Python using an integrated development environment (IDE), it still requires some programming in a simple scripting language. We plan to use LLMs to greatly simplify “data programming,” enabling users to create new programs using text prompts similar to how we instruct ChatGPT to generate written content or code.
ChatGPT, other LLMs, and generative AI for text-to-image creation captured the public imagination in 2022. Though these models are not directly applicable to document processing and the unstructured data processing market, they offer exciting possibilities for solving some of the biggest challenges it faces—processing semi-structured and unstructured data, quickly leveraging critical business information, and rapidly creating new IDP/UDP applications. We expect to greatly improve extraction quality and simplify the user experience for our next-generation IDP/UDP solution using these new advancements in AI.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.