By Purnawirman Purnawirman

Every project at super.AI, no matter the complexity, has two things in common: there’s an input and an output. What goes on in between is something we have explored in some of our other blog posts. But what guarantees the quality of the output?
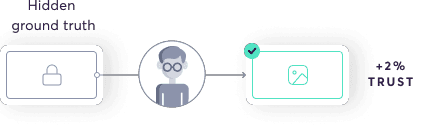
The answer to this question is ground truth data. Ground truth is a pair of input and output data used as a proxy for real truth. The closer the ground truth to the real truth, the higher the upper bound quality of the generated output.
At super.AI, we use ground truth data to provide the following:
Let’s look at these one by one in more detail.
Ground truth data guarantees high quality output by serving as a reference for measurement and training for super.AI labelers.
The first step to improving quality is measuring quality. Measurement is an act of comparing attributes of an object to another reference. If you want to measure the length of an item, you would probably use a ruler as the reference. If you want to measure the timespan of an event, you would use a stopwatch. When measuring the quality of a super.AI project, the reference is ground truth data.
Ground truth data is also used to train our labelers. We feed tasks made with ground truth data to our labelers. Then, we evaluate and improve their performance by measuring the labeled output they create against the ground truth output. Comparing the labeler’s output to the ground truth output allows us to do the following:
All of these in combination lead to higher quality output.
We can use ground truth to generate machine learning models that are of a high enough quality to assist human labelers under certain circumstances, thereby lowering your costs and providing a faster turnaround time. Over time, the quality of these models increases and we can come to rely on them more and more.
After labelling millions of data points and thousands of projects, super.AI can predict the cost and quality of your data labeling project even before you start paying for the service. We can provide a guarantee on the minimum quality of the labels you need and the labeling cost. Our in-house labelers are experienced and trained to meet the requirements of any projects you might have.
While the answer depends on the requirements of your project, it’s generally not as much as you might think. Nowadays, we can leverage pre-trained models (e.g., the Inception V3 model that has been trained on millions of images) and smarter ML techniques (transfer learning, one-shot learning, etc.) to train an image recognition model with a ground truth dataset containing under a hundred images. Talk to us to discuss how much data you need for your project.
We’ve also made adding ground truth easy, as you’ll see in the next section—you can even invite team members to help out—so super.AI is a great way to quickly amass a large ground truth dataset with very little effort.
We’ve made uploading ground truth data as simple as possible. You can do it directly through our dashboard or use our API. Additionally, you can review processed data points. Any output that your mark as correct gets added to your ground truth dataset automatically. For projects that use
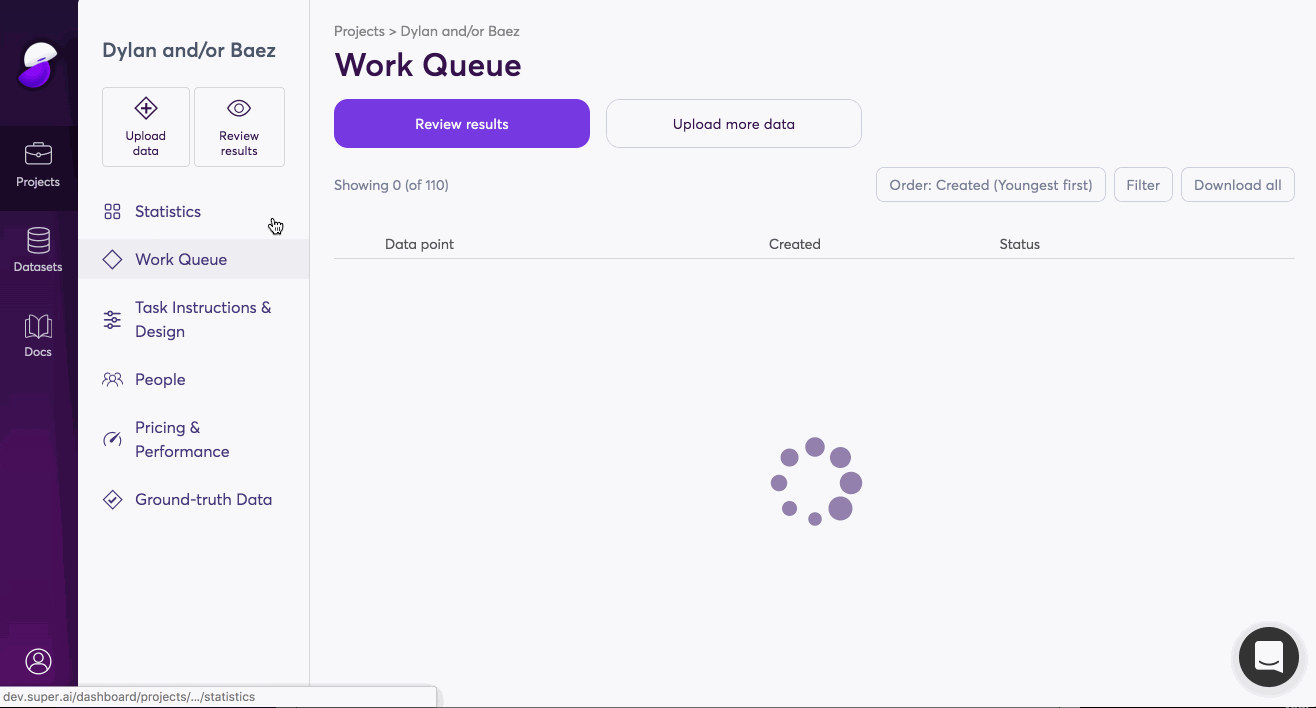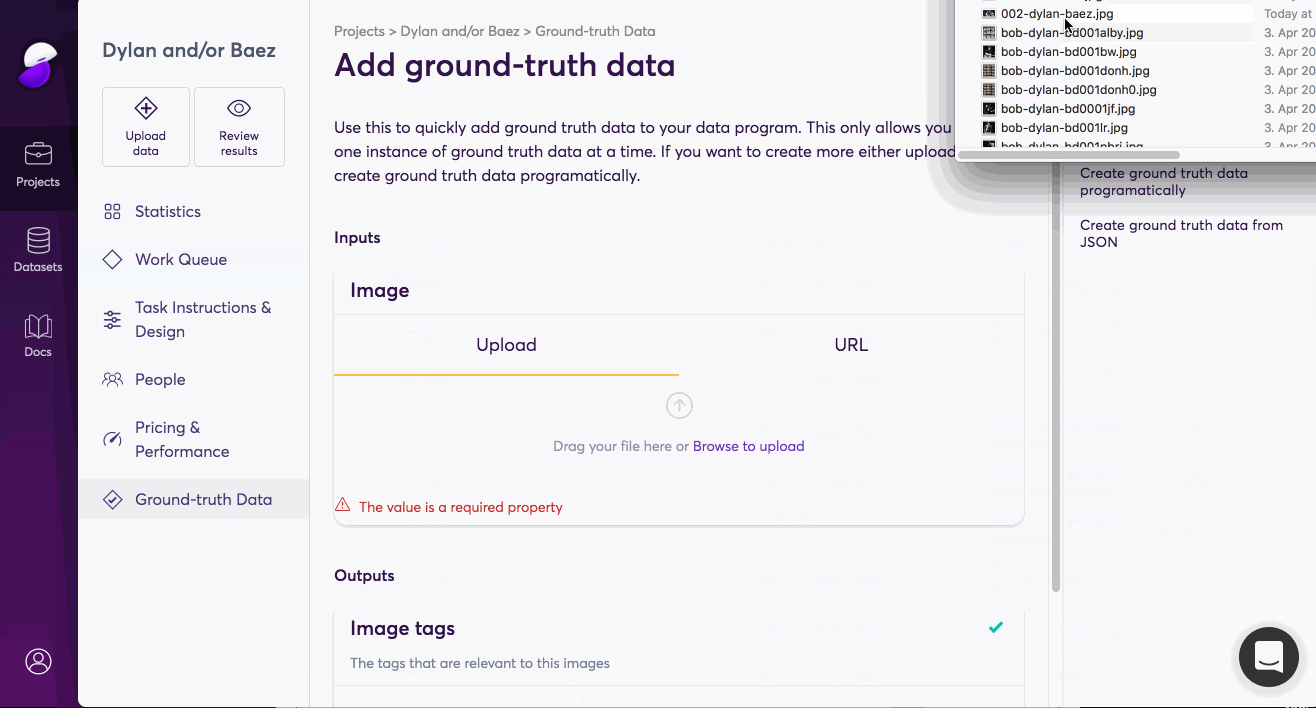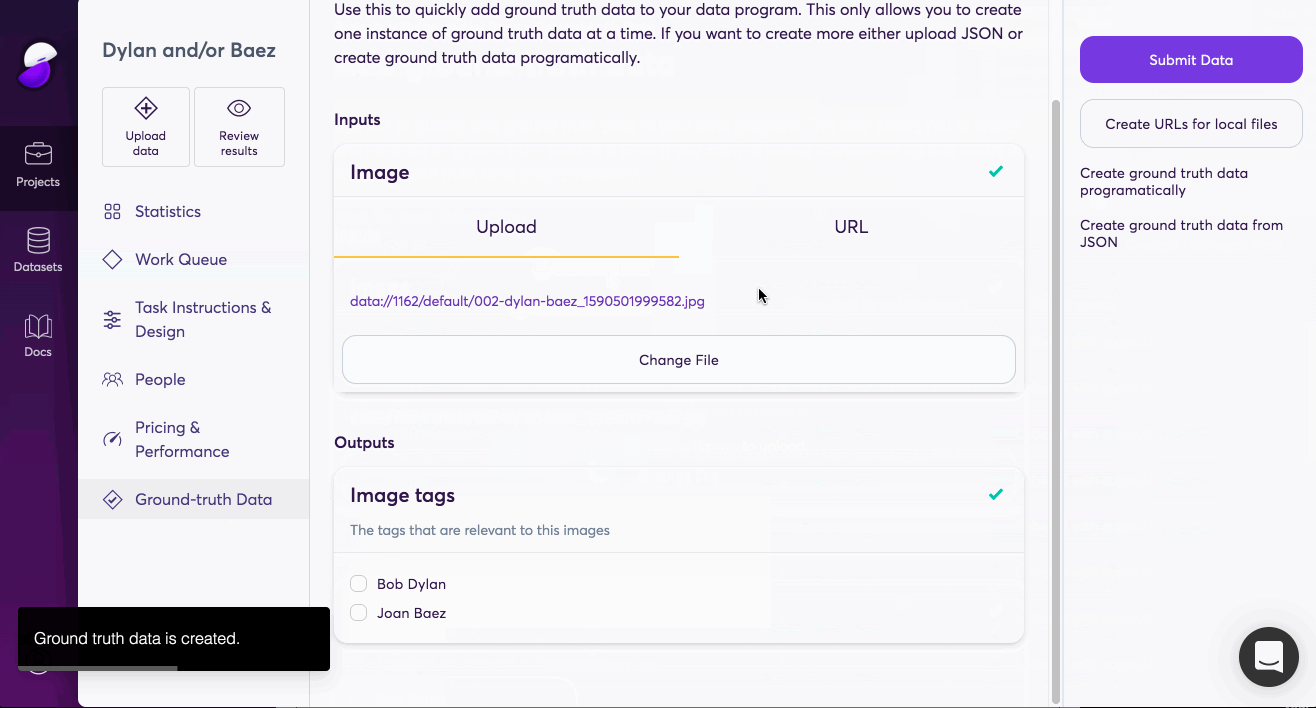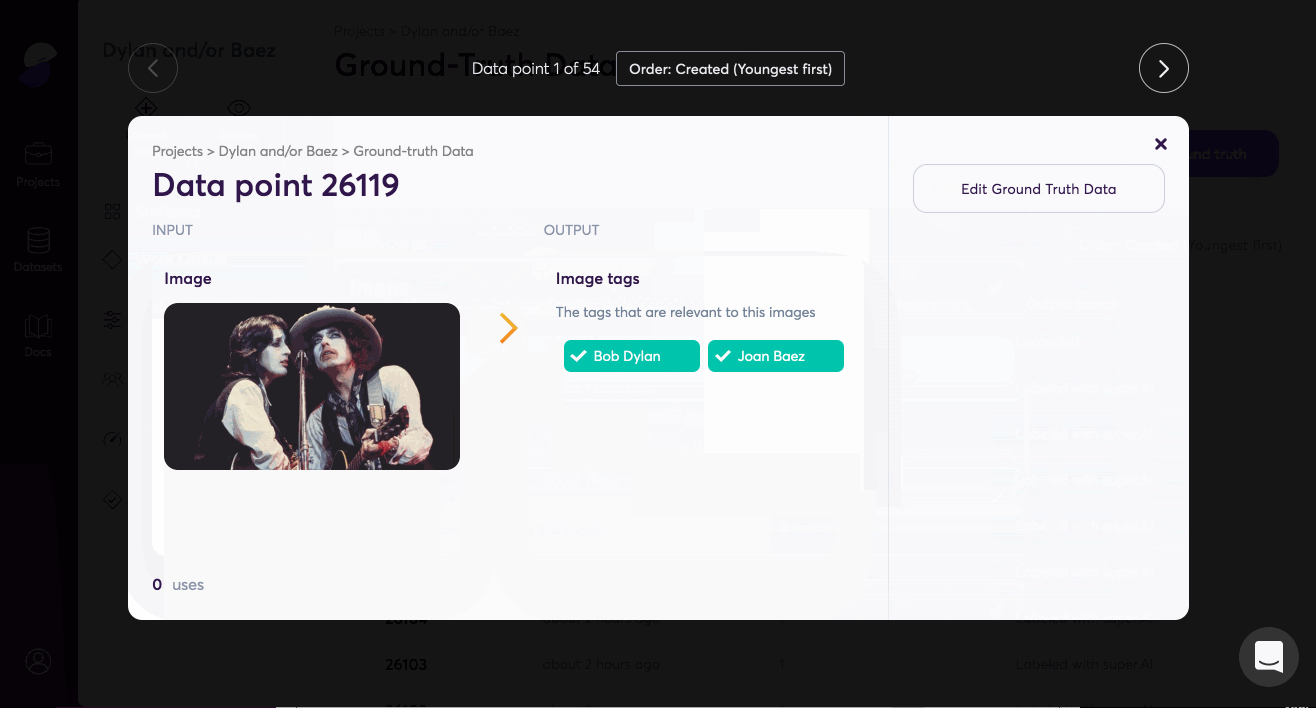
And that’s it. Every piece of ground truth data makes our quality measurements for your project more accurate, allowing us to home in on the exact output that you’re expecting and require. If you’re looking to automate your business with AI, talk to one of our sales reps to find out how to get started.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.