By Eddie Vaisman

The world of machine learning (ML) is complicated. If you’re thinking about integrating ML into your project, there are hundreds of questions you will quickly find yourself asking. How to store, version, and process your data? What development framework and hyperparameter optimization and resource management solutions should you use during the development and training of your model? That’s before you even look to deploy the model to production.
In reality, the messy, confusing world of ML makes most applications prohibitively expensive and error prone. Ultimately, as a recent IDC report shows, around 92 percent of organizations report one or more AI project failures.
At super.AI, we’ve developed data programming as a method of treating machine learning like the assembly lines that revolutionised the manufacturing industry. This simplified approach allows us to make data labeling—and therefore AI—affordable and accessible. This technique is housed within a larger system that means we can handle your entire ML pipeline from data management all the way through to a production model and continuous QA systems.
In this article, we’re going to show you how data programming works. You’ll see how super.AI breaks down complex raw input data into simple, easily processed tasks; how these tasks are processed; and how we combine multiple outputs into a single coherent output.
Our goal at Super.AI is to bring the four key elements of the machine learning world under one roof. From the data itself, through the model development and training and evaluation, to the deployment stage. This allows you to focus on what matters the most to you—delivering value to your customers—while we manage the complexity of the project.
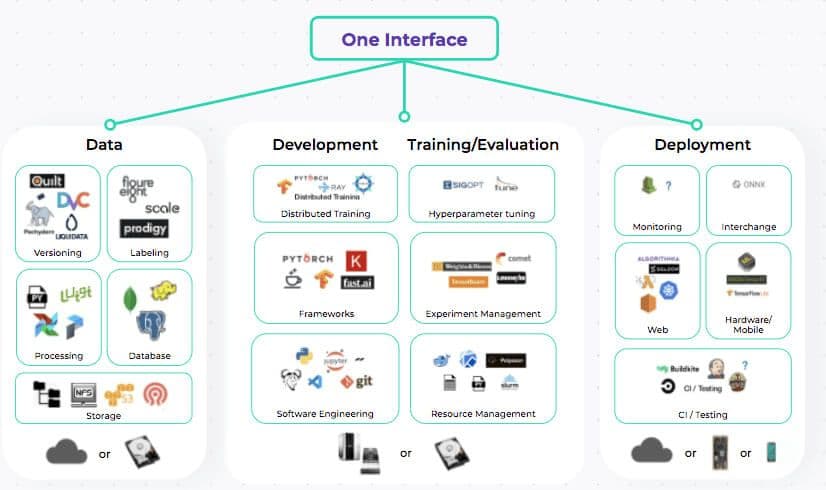
Our system is designed so that all the questions you have are boiled down to these essential ingredients:
The vast majority of the time, problems that people want to solve with ML are large, complex tasks that can only be completed by an expert or highly advanced, expensive-to-produce ML model, under the supervision of a PhD-educated data scientist. This makes the adoption of ML and AI into current businesses restricted to companies with the right financial and human resources to support such projects.
At super.AI, our mission is to democratize access to AI to companies of all sizes. That is why, similar to Henry Ford’s assembly line, super.AI’s data programs are designed to break down complex tasks into their constituent pieces, which are then processed individually before being assembled into the final output. This approach provides numerous benefits:
1) Cost savings
2) Quality increase
3) Scalability
In order to achieve this, we designed the AI compiler, which acts as the execution system for the data programming assembly line.
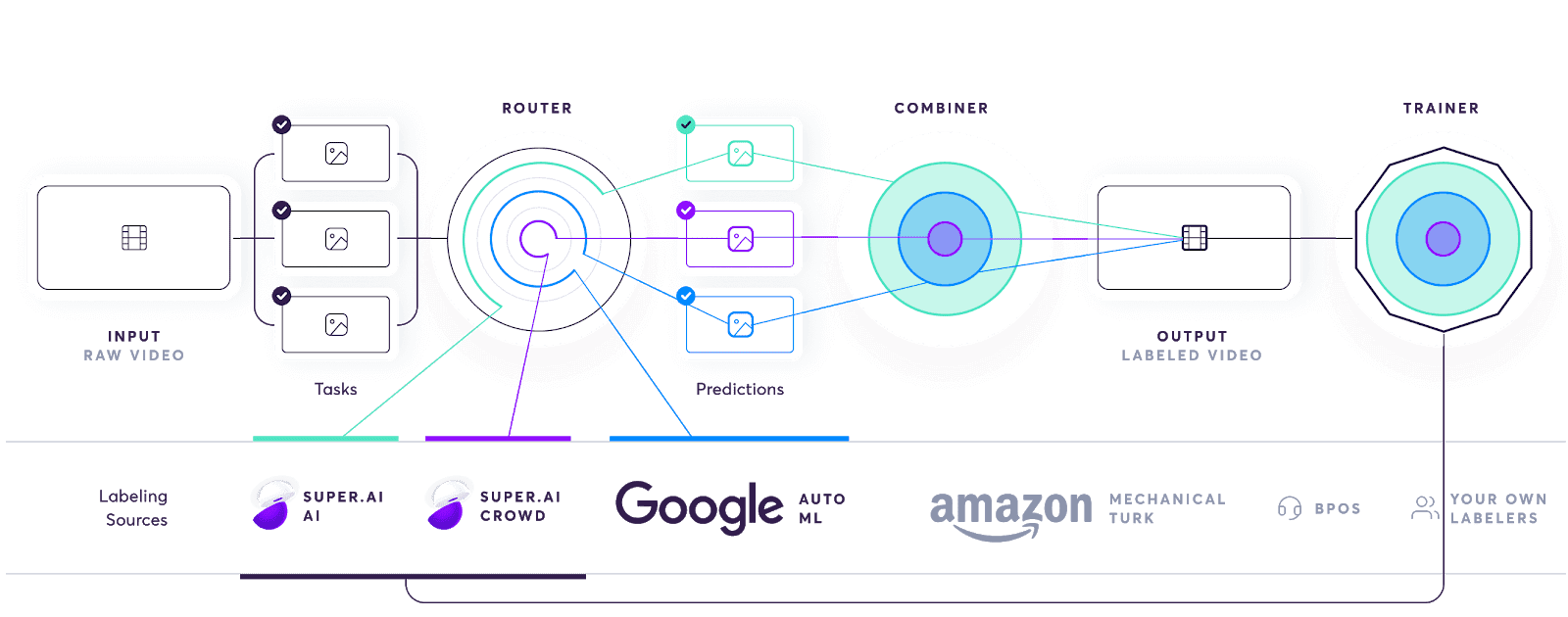
You can learn about the concept behind this system on our documentation’s AI compiler page. But we’re going to take a look at how the AI compiler functions in a specific real-world example, so you can see it functioning first hand.
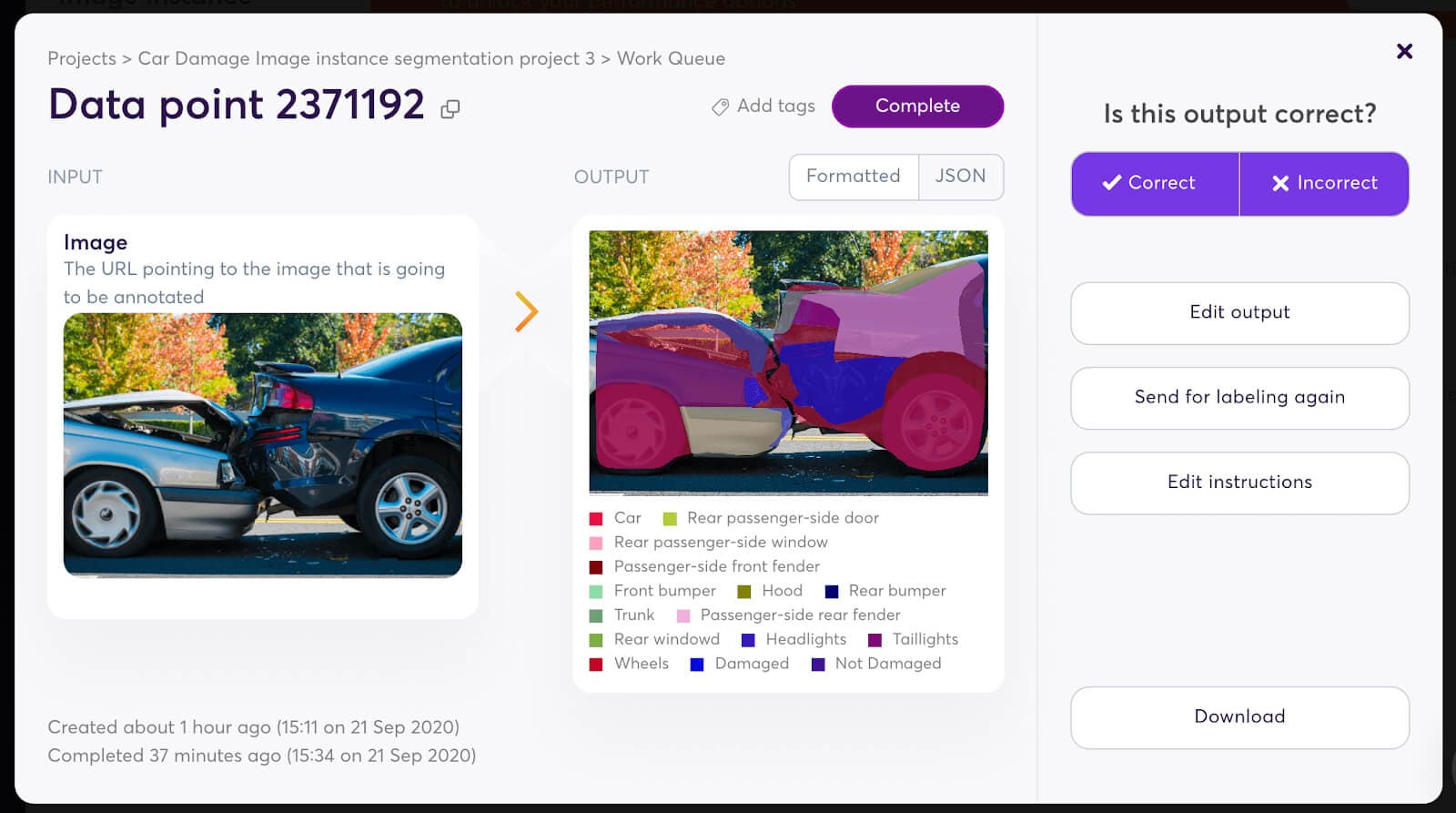
The big question: how do you go from a raw image to a labeled output, or from this:

To this:

At super.AI, we work with several customers from the insurance industry. For them, being able to automate their cost estimates in auto claims for damaged vehicles using AI provides significant improvements in customer experience by reducing cycle times. It also drives up efficiency and cost reduction for their business. To help them achieve their automation objectives, we adapted our image segmentation data program for the purposes of identifying damaged parts of vehicles. This data program is designed to identify and label (at the level of individual pixels) each instance of predetermined objects within an image. As in the example above, each pedestrian is a separate instance of the `pedestrian` class, and each vehicle and lamppost, etc., is likewise a single instance of its own class.
Adapting the image segmentation data program for the task of vehicular damage evaluation is an illustration of how the data program paradigm allows for flexibility. Simply by setting the classes to `Window` and `Body` and automatically creating subclasses `Damaged` and `Not damaged` for both, we could create a project suited to the needs of the customer.
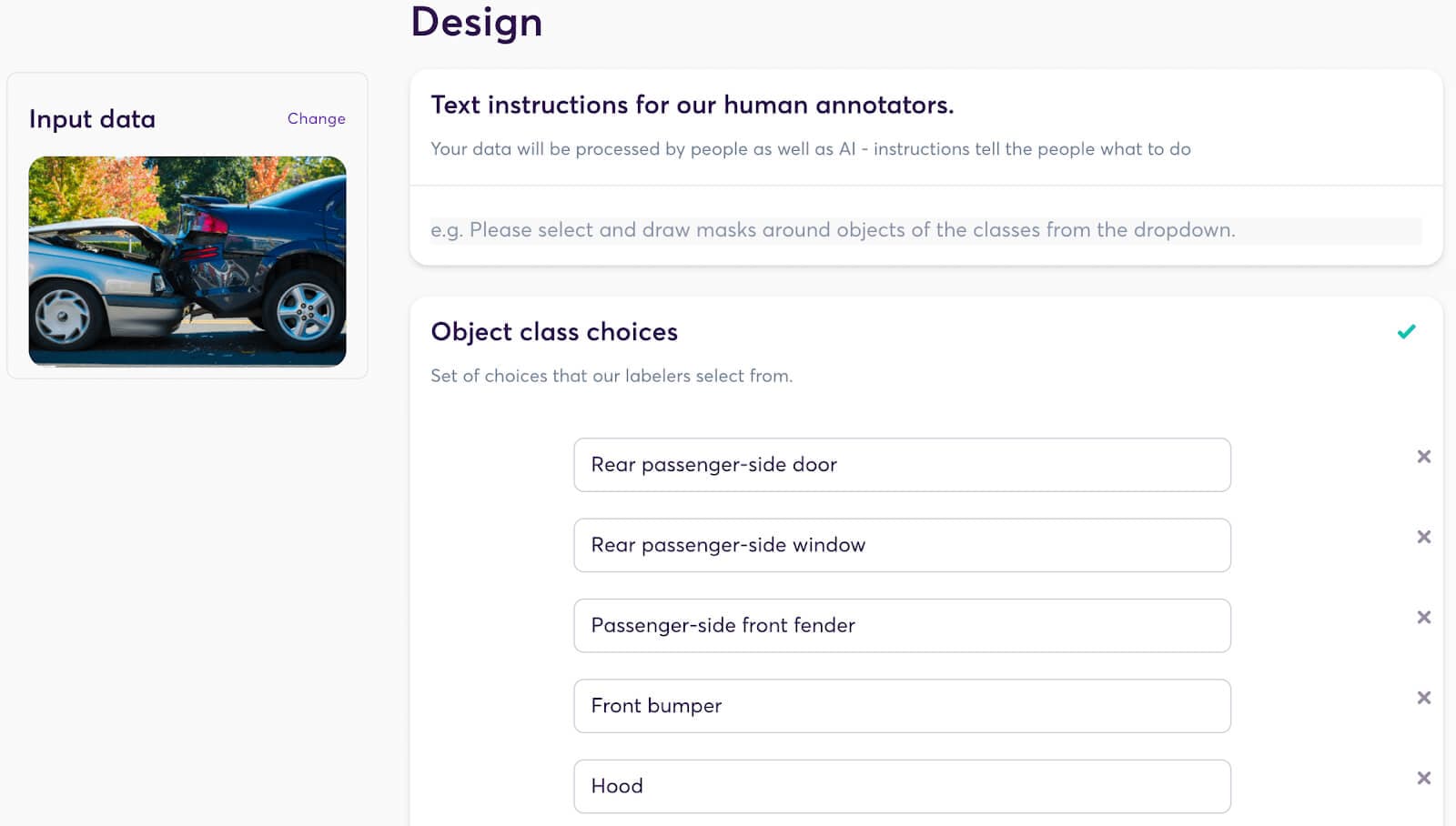
Once configured, the data program is ready to do its part in breaking down the customer’s task into simplified chunks.
The stages in breaking up and reassembling the task are as follows:
We use a mask R-CNN model to process the input images and provide a collection of masked images, each mask covering everything but one car in the image. It’s the assembly-line nature of the system that allows for this automated step. By simplifying the task in this way and breaking it up into multiple tasks per image input, the cognitive and physical load placed on the labelers is reduced.

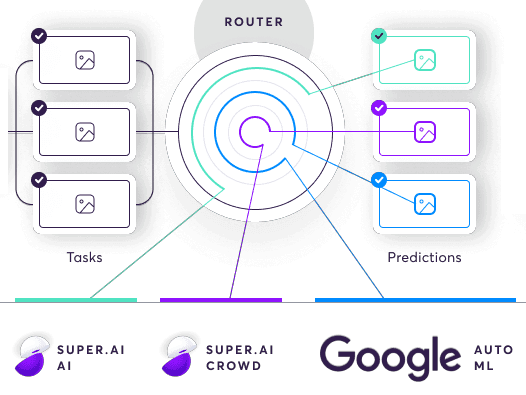
The AI compiler sends them to the router, which sits over a database of labeling sources. The router decides, according to the project’s quality, cost, and speed requirements, which labeling sources are best to handle the task and sends it there for labeling. The router can choose to use multiple sources for a single task, be that people, machines, or a combination of both.
The data program generates a labeling interface that our human labelers use to segment the image. The task instructions tell them how to segment the image, and a selection of tools make the process as painless as possible. They can use the line, bucket fill, or super pixel tools to easily add and subtract parts of the mask.
All labelers involved in the project complete a general image segmentation training program and undergo training on data specifically related to the project before labeling production data.
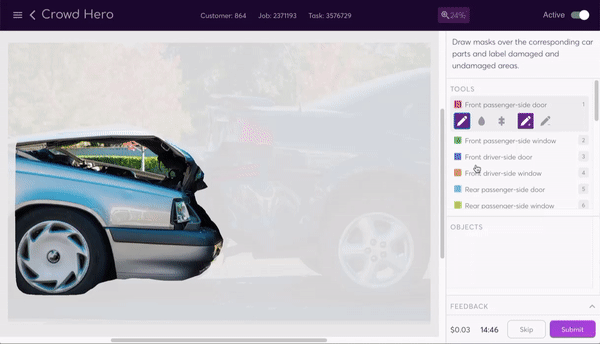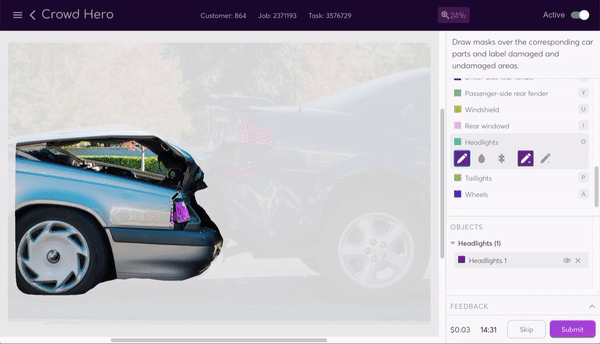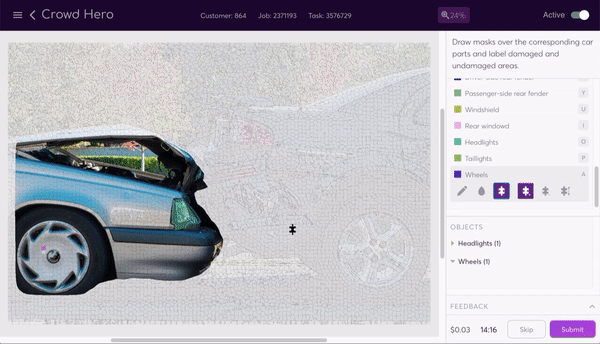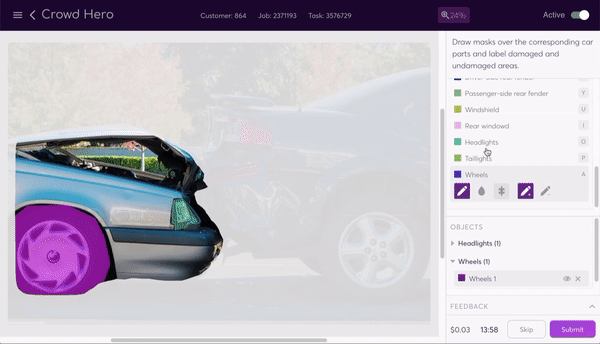
The router now performs its job again, sending out the segmented—and again pre-masked—images so that a new set of labelers can label damaged and undamaged parts of the now segmented body and windows. Being able to chain together different labeling tasks through different data programs in this way is a core value of the assembly line structure.
The labelers involved in this task, as in the previous step, have qualified through both general and specialized data training programs.
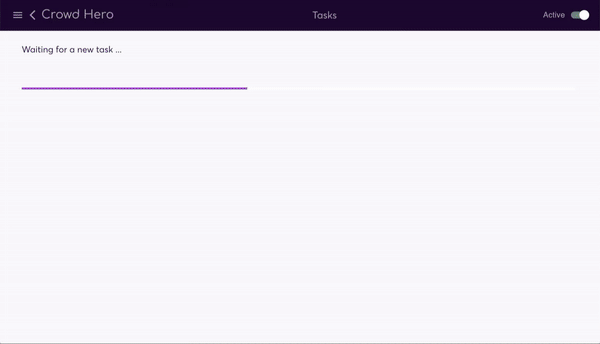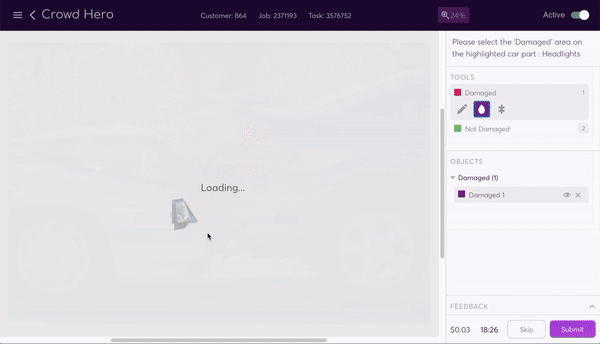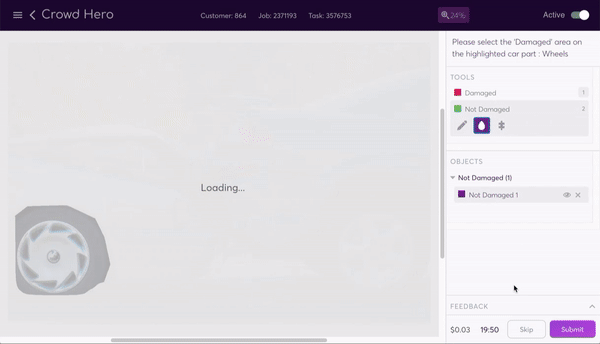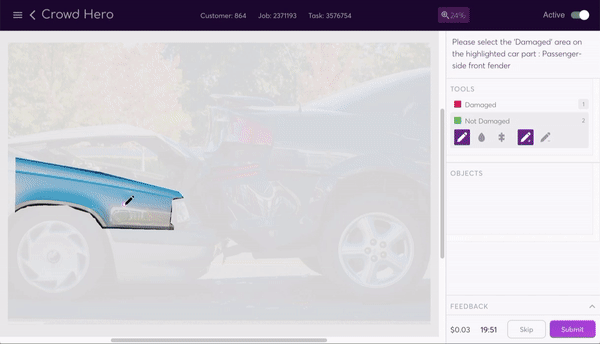
Once all the labeling sources have completed a task, the combiner produces a trust-weighted combination of them as the final output. This is one of the most complex parts of the system. The result is a high quality segmented image output with all body and window parts of all vehicles segmented and damaged and undamaged sections of each also labeled. This end product is achieved at the cheapest cost through the use of the lowest skilled labour possible, an option available to us thanks to the assembly line system we’ve created.
We’ve used image segmentation here to illustrate how super.AI can help make complexity simple. But we don’t only work on image inputs or segmented outputs. Our system is designed to handle any input and output that your project requires, whether it be text, video, or audio. Here’s an overview of how the same process works with video bounding box labeling:
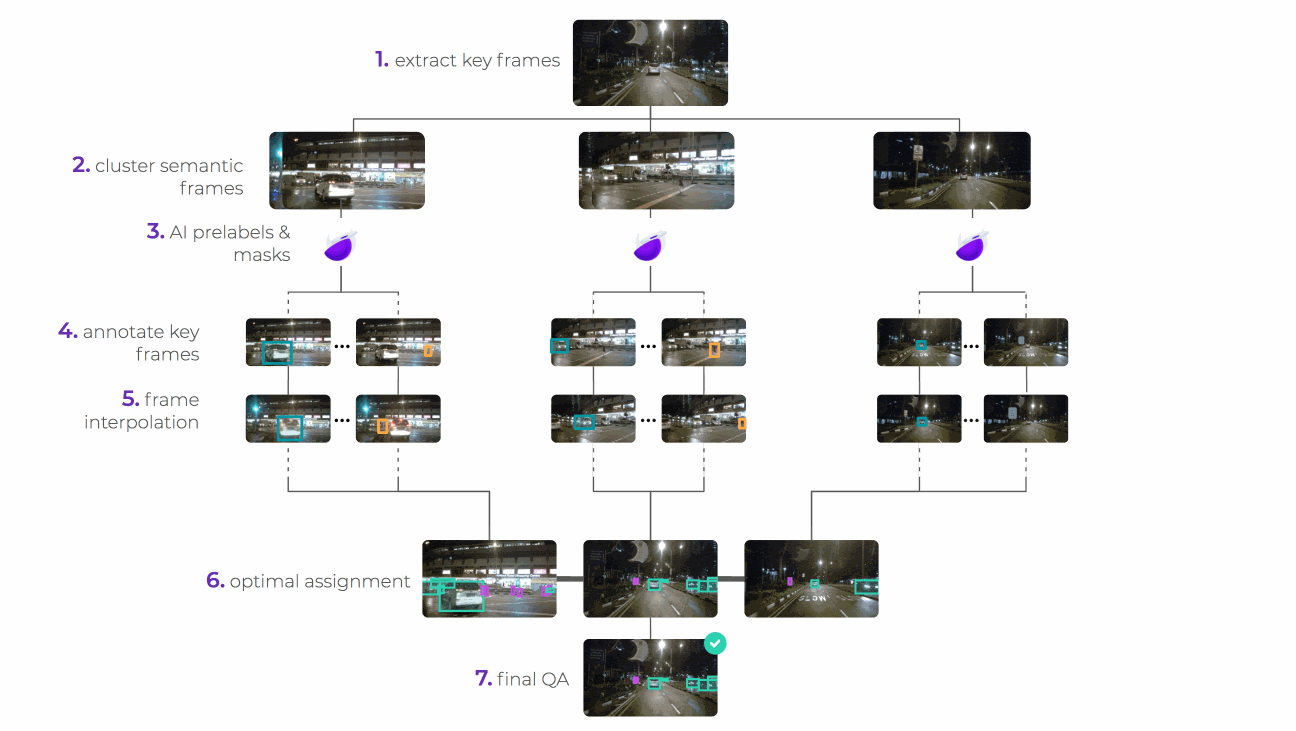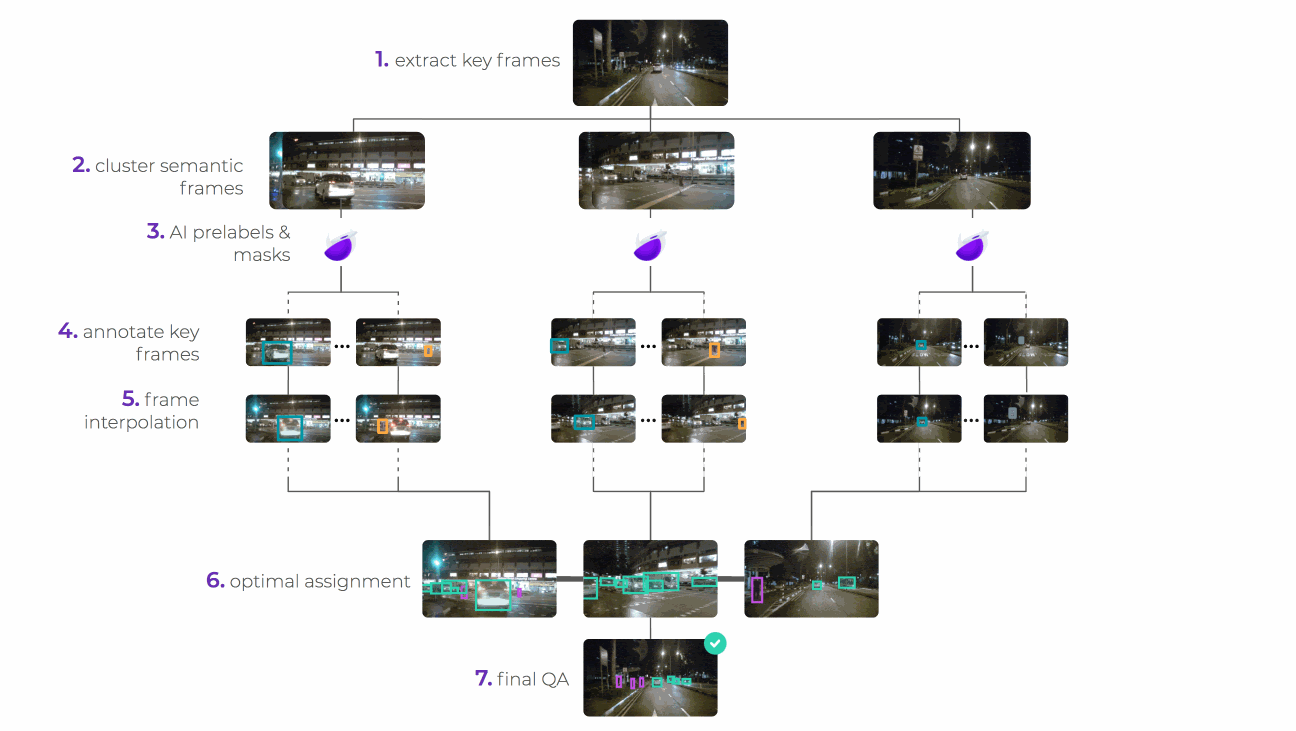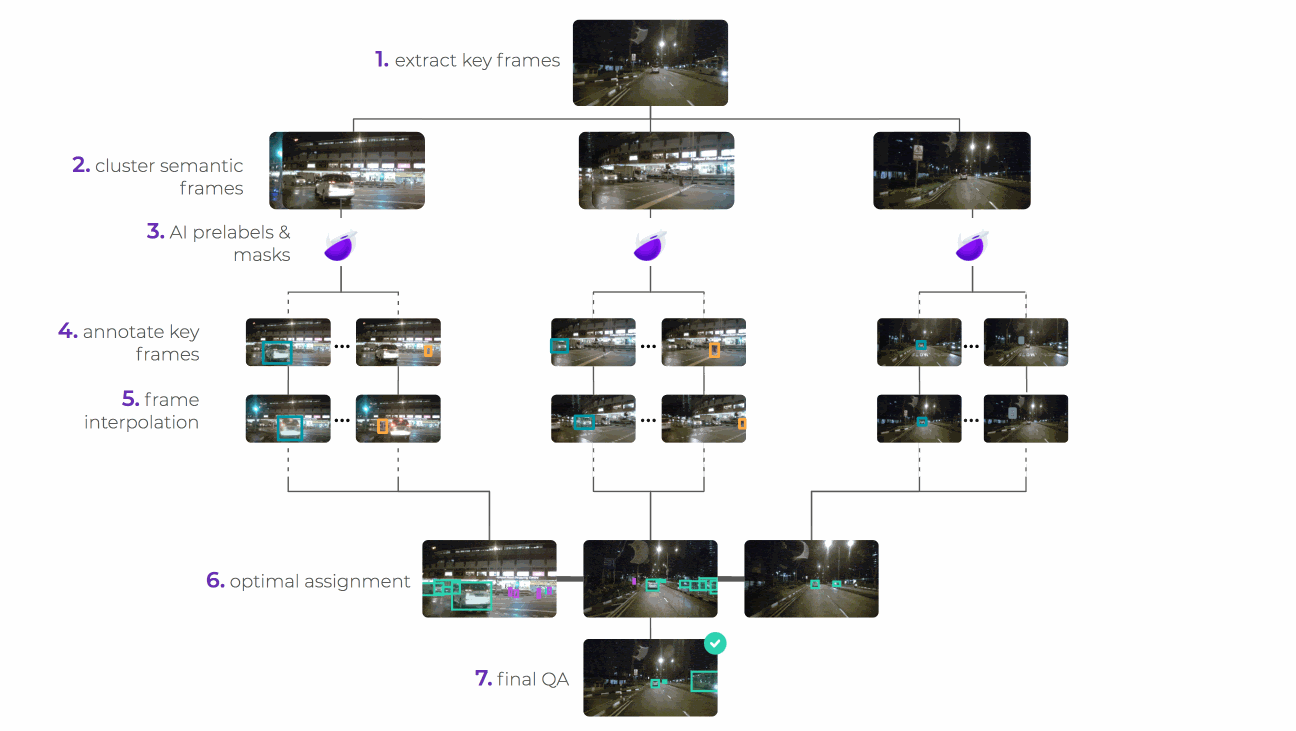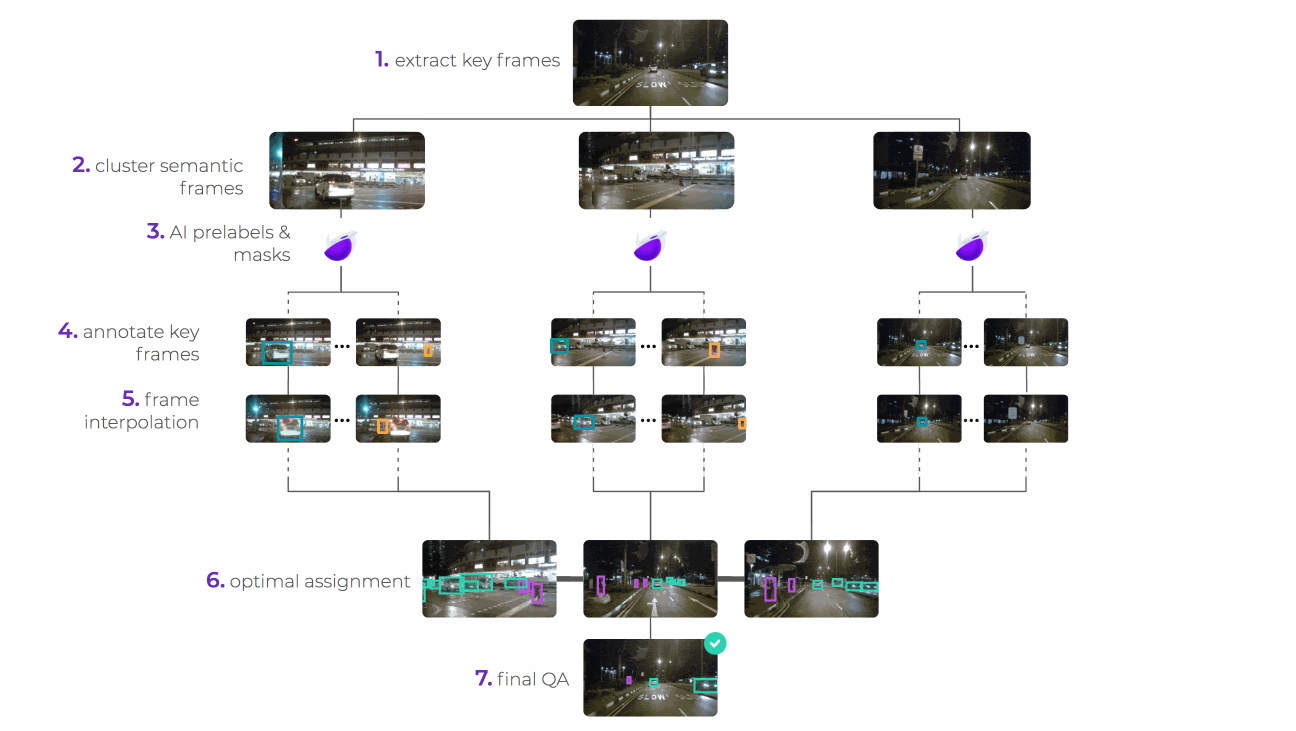
No matter what your project requirements, data programming is flexible enough to accommodate them. If you want to set up AI or machine learning projects at your company talk to one of our experts, who can advise you on the optimal way to create your own assembly line.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.