By Sina Youn

Organizations are under increasingly high pressure to protect customer and business data. In 2021, ransomware attacks rose by 13%—an increase as big as the last five years combined. This is a risky and costly trend considering an average total data breach cost of $8.19M for U.S. companies.
However, external threats aren’t the only concern for businesses. Since Europe’s General Data Protection Regulation (GDPR) went into effect in May 2018, privacy regulations have become stricter, and their enforcement stronger, with fines in Q3 2021 nearing €1B, 20 times more than in Q1 and Q2 combined.
Consumers are also becoming more concerned about data privacy, and demand more diligence from businesses handling their data, with 86% of Americans reporting that data privacy is a growing concern for them in a KPMB survey. Simultaneously, nearly two thirds of business leaders say their company should do more to strengthen existing data protection measures.
Data redaction, often used interchangeably with de-identification, anonymization, or sanitization, is the process by which personal information, and other sensitive or confidential information, is irreversibly removed from data so that a data subject can no longer be identified directly or indirectly. According to global privacy regulations, sensitive and personally identifiable information includes, but is not limited to:
Redaction has proven to be a straightforward approach for complying with privacy regulations, satisfying the highest IT security and privacy standards, as well as making data more accessible while maintaining privacy (e.g., sharing data with third-parties, data publication, data retention). There are various free and commercial tools available that help users streamline their redaction routine.
However, redaction becomes much more complicated with the diversity and complexity found within documents. While it's estimated that a significant portion of enterprise data is housed in documents that vary widely in structure and format, challenges similar to those seen with unstructured data types arise. For example, invoices serve to highlight the difficulties inherent in document-based information processing. Each business may structure and format their invoices differently, yet the core data—such as company name, billing address, and invoice date—remains consistent. The placement and presentation of these details, however, can vary greatly, appearing in different locations (e.g., top, bottom, within a table) or in various formats (e.g., handwritten), depending on the issuer.
This variability introduces significant hurdles in automating document redaction. Legacy solutions, including RPA-based redaction, often fail to consistently detect and redact information that doesn’t adhere to a predictable pattern or set of rules. The resulting processing errors and exceptions are not only costly but also difficult to accurately identify. Consequently, many companies continue to depend on manual redaction processes. Humans possess a flexibility and adeptness at recognizing similar information without a clear structure that legacy data processing tools simply cannot match. While tools like Adobe Acrobat provide features aimed at easing the redaction process, such as rule-based redaction or “select and redact,” they still largely depend on manual intervention, making the process slow, costly, and prone to errors.
Artificial intelligence (AI) offers an easy, cost-effective, and accurate way to overcome the limitations of existing manual and semi-automated redaction solutions. Intelligent Document Processing (IDP) platforms allow users to leverage different AI models and technologies depending on the task to accurately detect and redact any piece of information from documents—regardless of their formatting or structure. The benefits of using AI-based solutions built for document processing include:
Automated document redaction solutions built on an IDP platform cater specifically to processing documents, making it possible to handle a wide range of document types efficiently. This focus ensures users can meet their evolving needs without the necessity of purchasing new solutions.
Super.AI's IDP solution features automated document redaction. Fully compliant with privacy regulations (e.g., GDPR, CCPA) and industry standards (e.g., SOC, ISO, HIPAA), users are able to instantly and irreversibly remove sensitive or confidential information from documents quickly and reliably.
Super.AI IDP delivers the highest detection accuracy and near 100% anonymization quality at speed and scale. This means users can process and redact personally identifiable information (PII), such as names and social security numbers, from thousands of documents in a matter of seconds.
To get started, simply import machine-readable or scanned PDF documents via the UI or API.
Next, select the information that needs redaction. For example, automatically redact sensitive personal information within documents and tables such as:
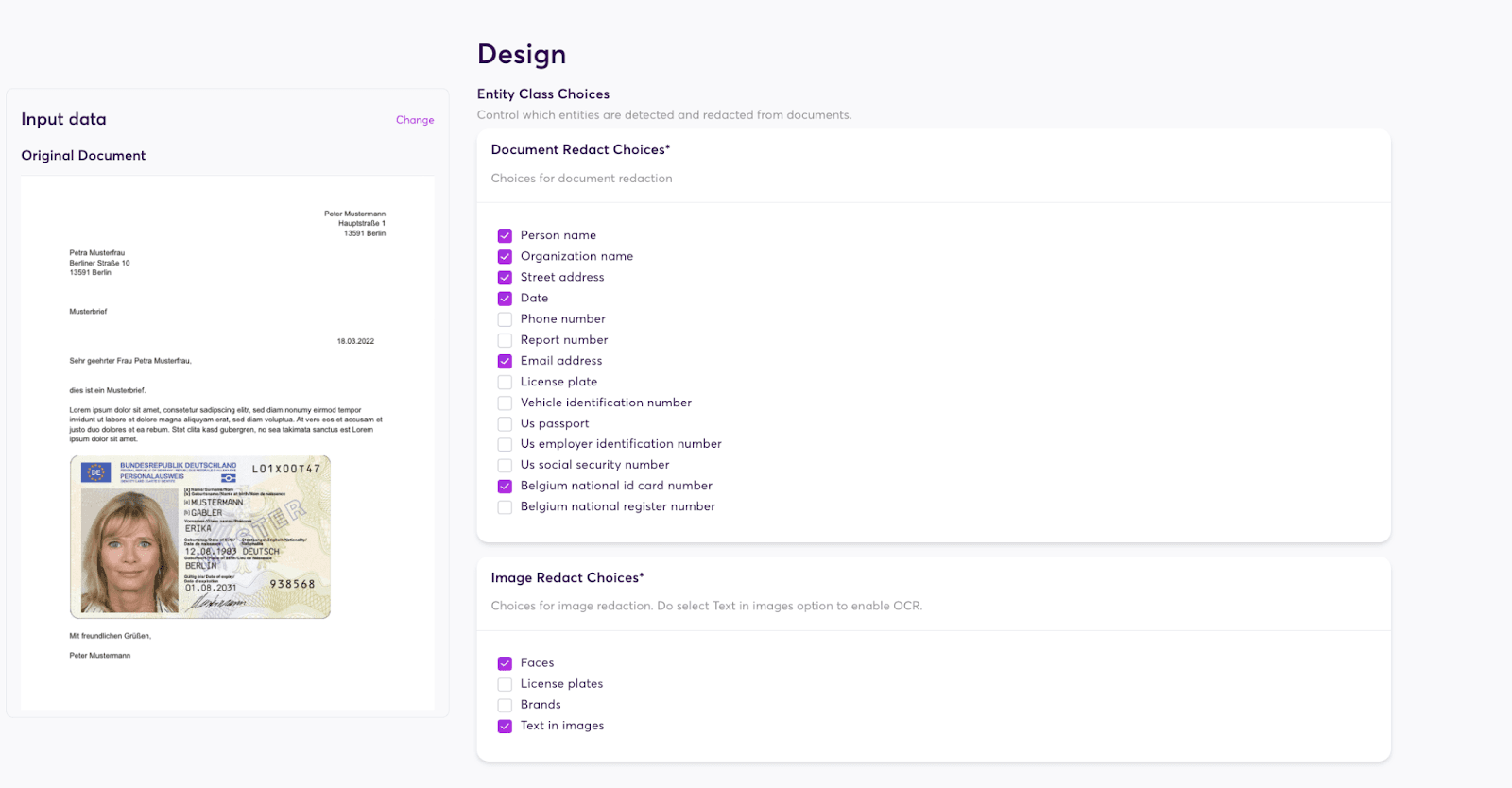
Selecting entities for redaction in Document.Redact.
Based on user defined settings, super.AI’s platform then routes the redaction task to the optimal machine learning models–running on our Meta AI infrastructure as well as on Google Cloud and AWS–for processing.

An example of Document.Redact detecting faces, person names, organization names, and street addresses for redaction.
Different AI models are used to precisely define the location of each piece of relevant information. Then, the output (bounding box locations) of multiple detection algorithms are compared, and/or combined if necessary, to return the best possible result. This assembly line approach to AI is what enables our quality guarantee.
Information is then processed by a document post-processing engine to obfuscate the entities/areas of interest. Depending on the PDF type, there are two options:
Both methods result in irreversible anonymization, meaning the redaction cannot be reverse-engineered.

Left: Redaction of a machine-readable PDF document and embedded image. Right: Redaction of a scanned PDF document.
The super.AI platform enables human-in-the-loop (HITL) post-processing for quality insurance (e.g., enlarging, adding, or deleting bounding boxes).
The system provides an audit copy so users can review findings quickly before redaction, as well as a mark up copy to quickly review redaction results for quality assurance. Users can review the data themselves, or add review-as-a-service by super.AI for a high-performing end-to-end solution.

Nationality ("DEUTSCH") and the country of issue (in logo and written text) has been added to the list of objects to redact.
Each processed document is saved as a new document file within the app, ready for download via the UI or API. The original document can be saved or deleted
In addition to the redacted document, the output includes metadata (in JSON format). This includes bounding box locations and object annotations, allowing users to leverage powerful analytics and further automate document processing.
This works for machine-readable PDFs, scanned documents, and embedded images. For the latter two, optical character recognition (OCR) is enabled so that not only character strings will be detected, but also correctly classified (e.g. names).
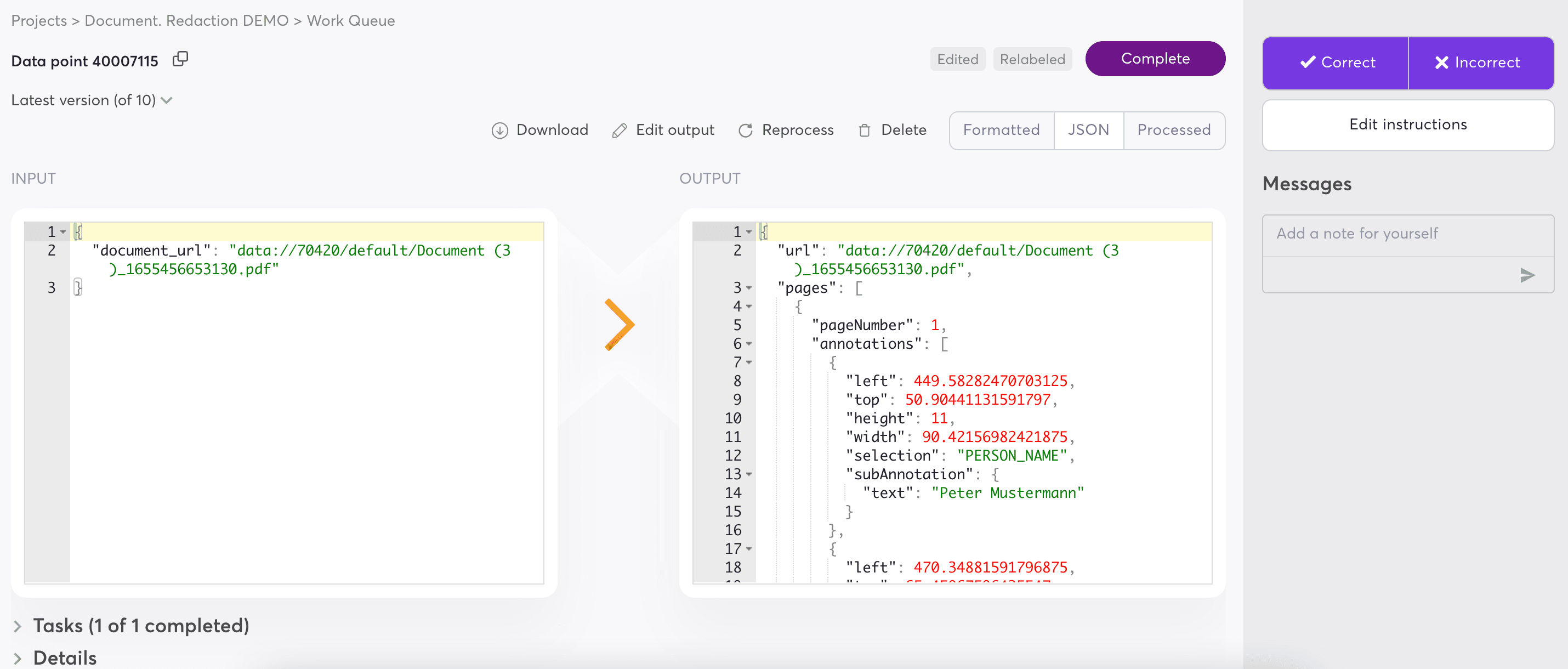
Example metadata output from Document.Redact.
Super.AI Intelligent Document Processing (IDP) has full legal admissibility and is designed for business users and technical users alike to address the growing imperative for organizations to effectively manage data privacy compliance and minimize IT- and cybersecurity risks. Data privacy is fast becoming the rule rather than the exception. Applications of super.AI IDP include:
For more information about automating redaction with AI, check out the following resources:


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.