By Sina Youn

So, what’s your data redaction routine?
If that question made you cringe, don’t worry, you’re not alone. Amid increasing data privacy regulations for how information is gathered, stored, used, and shared, PwC found that 66% of C-level executives say their organizations have no formal data protection processes or technologies in place. That means most still apply ad-hoc/as-needed approaches to anonymizing data, typically relying on manual processing to redact sensitive information or deleting data en masse, losing the opportunity for analysis and insights altogether.
It’s a little like going to the dentist. We all brush our teeth right before that dreaded check-up and hope for the best, but we know that establishing and maintaining a rigorous dental hygiene routine is the correct approach to ensuring cavities (and every other unwanted oral issue) don’t happen in the first place.
That’s where automated data redaction comes in. It's the secret to fresh, shiny, privacy-compliant data usage, storage, and handling—every day.
Globally, more stringent and more enforced data privacy regulations are becoming the norm. The EU introduced the General Data Protection Regulation (GDPR) in 2018 followed by the California Consumer Privacy Act (CCPA) in 2020. Both regulations set new standards for data privacy impacting any business activity or transaction in Europe or California, whether a business has operations in those regions or not. And the expectation is that similar data privacy frameworks will cover the majority of the world’s population in just the next couple of years.
The reality is that modern business operations both generate data and rely on data. And lots of it. This ever-growing body of digital data poses ever-higher business risks. The larger the amount of data used, stored, and flowing through the organization, the higher the likelihood of losing control over sensitive data in a cybersecurity breach or violating increasingly mandatory privacy laws. And, unlike feigning the flu to skip a dentist appointment, there’s no hiding from the seriousness of data breaches or privacy violations both in terms of direct costs as well as reputation damage.
A recent AIIM report found that information management professionals estimate that unstructured data makes up more than 50% of company information. No surprise there, but, when combined with organizational unpreparedness for secure data sharing amid the recent shift to remote and hybrid work models, data breaches and regulatory compliance violations become looming threats that are widening in scope.
A rigorous data redaction routine is the best way to ensure safe handling, storage, and sharing of data containing personally identifiable information (PII) and other sensitive data.
Redacting data would be a piece of cake if it wasn’t for unstructured data. Unstructured data poses a unique challenge for data redaction since identifying sensitive information within unstructured content, such as emails, documents, images, and videos, is complex work, requiring unwavering attention to detail and understanding of the content.
In particular, large volumes of non-text based forms of unstructured data, such as images, now represent the foundation of many business processes as well as research and development work in industries as varied as autonomous vehicles, medical research, and financial service technology. With increasing data privacy requirements, these organizations are hitting a data-anonymization wall, unable to accurately de-identify data at scale.
And now for the good news (no, your dentist appointment didn’t get canceled, sorry). Artificial intelligence (AI) makes it possible to quickly locate and automatically redact sensitive information from virtually any data type.
As the volume of unstructured data grows, AI makes it possible to automate redaction to ensure sensitive information remains protected. Applying AI to automate PII redaction enables data processing, saves time, limits risks, and minimizes human error—an unavoidable pitfall of manual anonymization. In short, AI-based redaction ensures the highest level of data privacy and regulatory compliance.
[insert happy dance here!]
Image.Redact is a no-code AI solution built specifically for image redaction. Fully compliant with privacy regulations (like GDPR and CCPA), users are able to immediately upload data, define the objects that require redaction, then let Image.Redact do the rest.
Built on our Unstructured Data Processing (UDP) Platform that combines the best AI models with human-in-the-loop, Image.Redact delivers the highest detection accuracy and near 100% anonymization quality at speed and scale. That means you can process and redact PII, such as faces and license plate numbers, from thousands of images in just a few seconds.
We built Image.Redact to unblock enterprises and organizations that need to anonymize their images at scale, with high precision and recall.
So, how does it work?
Image.Redact is a no-code app. That means it’s designed to enable immediate image processing by anyone–no AI or data science expertise necessary. It’s also ready to integrate with your existing products and services. We have a well-documented API with ongoing post-integration management.
To get started, you simply import your image data. You can upload data directly within the UI or via the API.
Next you select the kinds of information you want to redact. You can automatically redact faces, license plates, brands, or text within images.
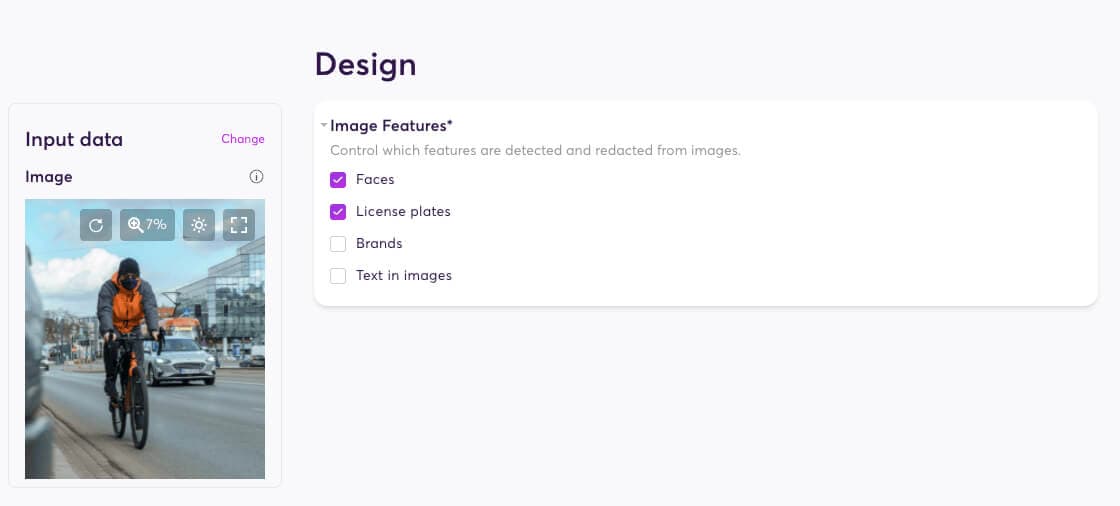
Based on your chosen settings, super.AI’s UDP platform routes the redaction task to the optimal machine learning models–running on our Meta AI infrastructure as well as on Google Cloud and AWS–for processing.

The models’ job is to detect the desired entities (in the given example: faces and license plates) and precisely define their location. Then, the output of multiple detection algorithms (called “bounding box location”) is compared (and/or combined, if necessary) to apply the best possible result. This “AI assembly line” is what enables our quality guarantee.
This information is then processed by an image post-processing engine to obfuscate the entities/areas of interest. When blurring is applied to obfuscate, Image.Redact uses a box or Gaussian filter and dynamically calculates the kernel size from the image resolution. This way, it’s not possible to reverse-engineer the blurring and “get back to the original”.

The super.AI UDP Platform enables human-in-the-loop post-processing of false positives and negatives for further quality assurance, and for adding objects to blur (e.g. texts). Your own team can review (“internal human-in-the-loop”) or you can add review as a service by super.AI (“external or crowd-in-the-loop”).
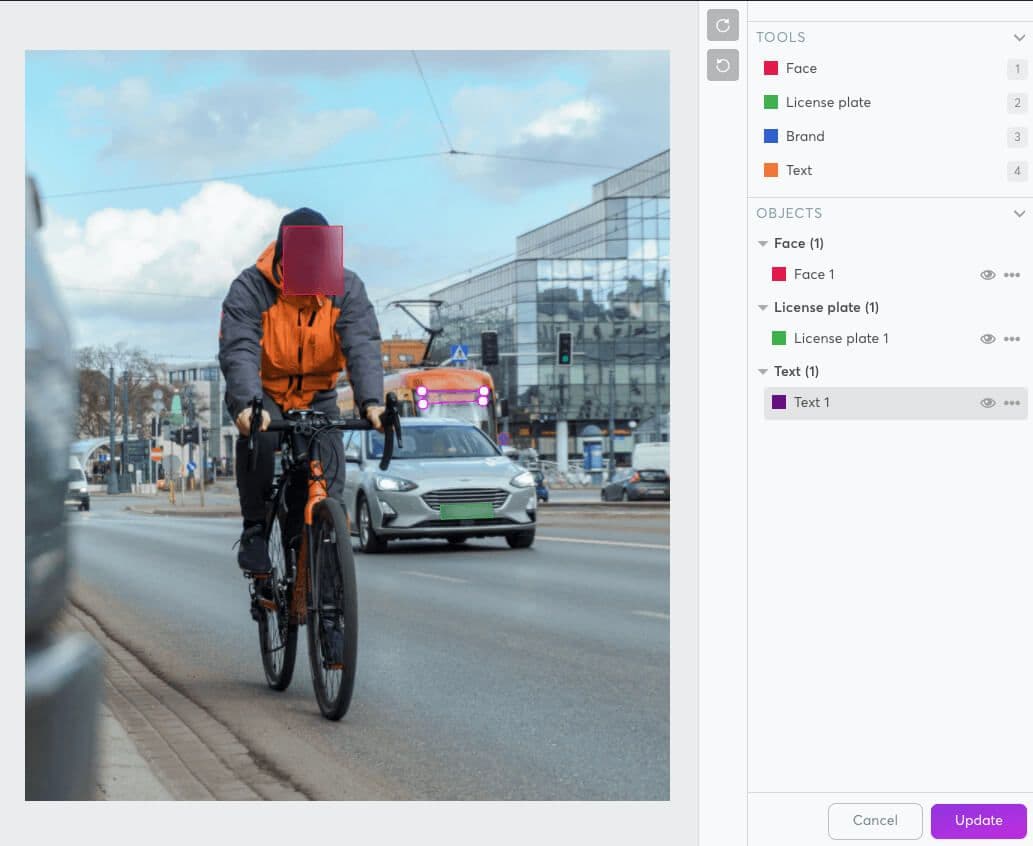
Each processed image is saved as a new image file within the app, ready for download directly via the UI or API. Original data can be saved or deleted.
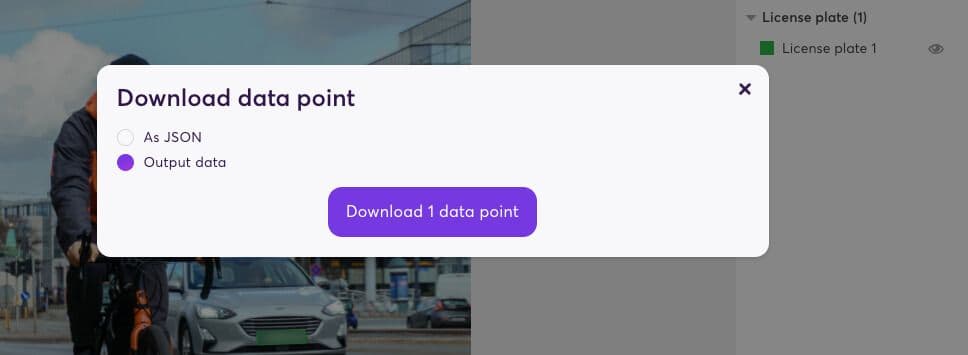
In addition to the redacted image, your output includes metadata (in JSON format). It includes bounding box locations and object annotations, allowing you to leverage powerful analytics and data preparation.

Image.Redact is designed for business users and technical users alike to address the growing imperative for organizations to effectively manage data privacy compliance and minimize cybersecurity risk as part of day-to-day operations. Data privacy is fast becoming the rule rather than the exception.
Applications of Image.Redact include:

Don’t let image data redaction give you a toothache. Connect with us for a live demo and discussion of your data redaction needs. If you’re interested in learning more about AI-powered redaction, check out the following resources:


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.