By Ralf Banisch

Speech Recognition—sometimes referred to as automatic speech recognition (ASR), speech to text (STT), or computer speech recognition—is the task of converting spoken language into text. ASR processes raw audio signals and transcribes them.
ASR falls under the family of “conversational AI” applications. Conversational AI is the use of natural language to communicate with machines. It typically consists of three subsystems:
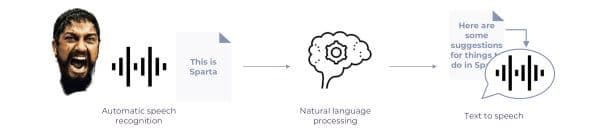
Each of the three subsystems integrates multiple neural networks to create a seamless experience for the end-user. Neural networks are a programming paradigm that enables a computer to learn from observational data using a unique architecture of small functional units (the neurons) which are wired together in a manner mimicking a rudimentary model of the human brain.
The most prominent voice-driven applications that have embedded into our day-to-day lives are voice assistants such as Apple's Siri, Amazon's Alexa, Google Assistant, as well as Microsoft's Cortana. These question-answering systems have been improving at a tremendous pace in the last few years due to advances in deep learning and big data. As an example of the forward momentum, Google just announced Meena, a “2.6 billion parameter end-to-end trained neural conversational model” designed to handle wide-ranging conversations.
Our previous posts explored NLP techniques such as sentiment analysis and named entity recognition (NER).
Here, we explore the first subsystem of a conversational workflow: automatic speech recognition. We explain how it works, explore some use-cases, and see how you can apply it in your business.
At its heart, speech recognition is a 3-step process:

The acoustic model and language model are types of neural networks.
ASR models are evaluated using the word error rate (WER) percentage. This is the percentage of the total words the model inserted, deleted, and substituted divided by the length of the words in the actual transcription.
There are numerous challenges faced by ASR. Here are just a few:
The most precise way forward, as is often the case in machine learning, is to generate more relevant labeled training data. By relevant, we mean training data that is more representative of the population of situations that the model will encounter once deployed.
The more high quality and relevant labeled data you train your model off, the better it becomes at handling noise, accents, and other variations in speech.
In line with its versatility, ASR has a wide range of use cases. With the advancements in conversational AI, it would not be surprising for speech to become the dominant user interface in the coming decade.
Some notable use cases include:
If you think that your business or project could benefit from ASR, it’s pretty easy to start. Kaldi and Nvidia's NeMo (standing for neural modules) are popular open-source toolkits for speech recognition.
But before you begin using one of these frameworks to build a model, you will need to produce a relevant labeled dataset to train the model.
With super.ai, you can provide us with your raw audio files and we’ll transcribe the audio for you, returning a high-quality training dataset that you can take to train and tailor your ASR model off.
If you’re interested in learning more, or have a specialized use case, reach out to us. You can also stay tuned to our blog, where we’re continuing to run a series of posts covering different aspects of NLP.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.