By Brad Cordova

In classical software engineering, dependency debt is a key contributor to code complexity and technical debt. In ML systems, data dependencies carry a similar magnitude of debt but are far more difficult to detect. Code dependencies can be analyzed via compilers and linkers. Machine learning demands the development of a similar tool to identify these data dependencies.
This is the fourth in a series of posts dissecting a 2015 research paper, Hidden Technical Debt in Machine Learning Systems, and its implications when using ML to solve real-world problems. Any block quotes throughout this piece are from this paper.
Our last post in this series explored input entanglement and the dangers of training a model on another model’s output. Here, we continue to explore the importance of quality input data and introduce a new danger: feedback loops.
Unstable input data — meaning data that changes over time — forms a particularly tricky form of data dependency debt. It occurs when, in order to move fast, the ML algorithm consumes data directly produced by another system.
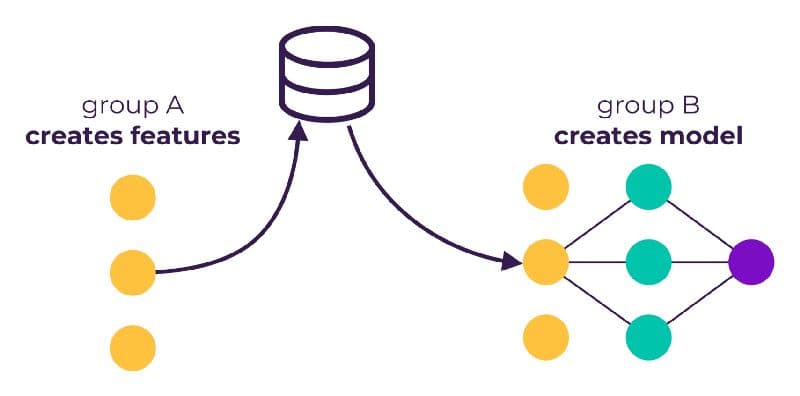
The input data could change explicitly: for example, when an engineering group in charge of the data — separate from the engineering group in charge of the model — changes it. The data could also change implicitly: for example, when another ML system gets updated. The problem is made worse by the fact that such updates to external systems can happen at any time.
Let’s consider a flawed revenue forecasting model that always over predicts revenue by $1M. Let’s say another ML model consumes that output and predicts headcount. The second model is accurate, and implicitly always subtracts $1M from the other model to get its accurate predictions.
But what happens now, when someone realized the revenue forecasting model is inaccurate and fix it? Well the headcount model doesn’t know the revenue forecasting model is now correct and continues subtracting $1M from that model. And so as a result of fixing the revenue-predicting model, the headcount model is no producing incorrect predictions, because it is not ingesting a stable input.
The way to fix this is to create an alert system for when the distribution of input features changes above a certain threshold. You can create an aggressive or conservative threshold based on how important the application is.
Another practical tip is to track the provenance of data in your system. If the version of any upstream process changes, you don’t adopt the new version until you update the downstream processes. This means freezing the version of inputs until you update the whole system. There are tools which can automate this.
When designing ML algorithms, some input features are more important than others. Sometimes a small fraction of input features account for more that 95% of the model’s performance.
It’s common over the model’s development lifetime to accumulate lots of features, a large portion of which become redundant. On their own, these features neither significantly hurt nor help the algorithm. Individually or in an academic scenario they are harmless, but in a larger ML system they can lead to instability within the system and create vulnerabilities.
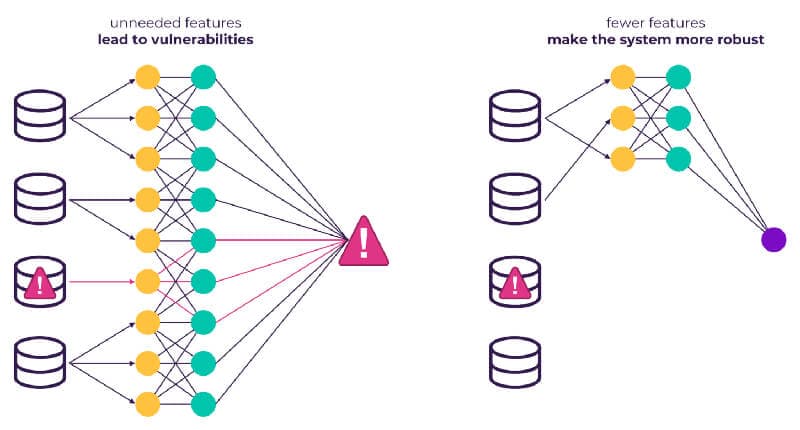
Here are some common ways in which unimportant input data can arise:
For example in the first version of your music recommendation system you find that using someone’s device type as a feature is highly correlated because you are only operating in one state. Later, you realize that using their listening history and their likes is a much better indicator. You continue to develop the system but forget to take out the device type feature, which is actually lowering the quality of your model.
In a rush, you added all the statistics you could think of (mean, mode, IQR, skew, kurtosis), when in reality only the mean is useful. Let’s say that later the function which calculated skew changed by accident. Even though it’s not important, it then spiked the values and made the ML model useless. The more useless features you have, the higher probability of introducing an error without any of the benefits worth taking such a risk.
Let’s say your fashion recommendation model is 96% accurate with two features: past buys and Pinterest likes. You add 55 new features that gets your model to 96.1% accuracy. Like in the bundled features case with the additional 55 features there are many things that can happen to mess up the model. It’s not just the total accuracy you need to account for in the real world, but rather the benefit-to-risk ratio.
Let’s say you have an activity recommendation algorithm, and you want to add gender as a feature because you think it can add signal. You also add their name as a feature because it can also determine signal for their gender. In reality, gender causally determines someone’s name; name doesn’t causally determine gender. But ML models are statistical and can’t determine this causal relationship, and in general will weight these two features equally, or may even by chance choose the name feature. This can be a problem later we have gender neutral names like Jordan, Casey, Jessie that can start causing errors as the correlation breaks down.
The solution here is to not only consider the ultimate accuracy of the model but to consider the ratio of the accuracy to the complexity of inputs. If you have a small number of simple inputs, there is a much lower probability something will go wrong. Since ML is so unwieldy, this can serve you well in the real world. If you have features which don’t add a lot, then you should think carefully about whether the small improvement is worth the risk.
There are other tools you can use to assess feature importance to help you remove unnecessary features. But ultimately it’s a subjective decision based on your needs. This, however, is not a concern in academia.
“One of the key features of live ML systems is that they often end up influencing their own behavior if they update over time.”
This can make it very hard to predict the behavior of a model when it’s pushed into the real world. Detection of these feedback loops is most difficult when the rate of change is slow. They are easier to detect when models are updated frequently. For example, detecting a data shift that occurs directly after deploying a model is much easier than detecting a related data shift that occurs a number of months after deploying a model — the causal chain is almost certainly shorter.
Direct feedback loops occur when the output of an ML model influences the future input features which the model is trained on. This causes the behavior of the ML model to converge into an arbitrary artificial solution that performs poorly.
For example, consider a song recommendation ML model on a music streaming service. The ML model presents 5 songs and the user chooses one — Bohemian Rhapsody. In truth, their ideal song — Kraftwerk’s Autobahn — might actually be found outside the pool of songs the model has selected for presentation. The model, seeing a user selecting Bohemian Rhapsody, modifies its behavior to show the user more operatic prog and glam rock, which the user obligingly listens to. The model starts honing in on an increasingly specific target that might lie quite far from the user’s actual preferred taste — avant-garde electronic.
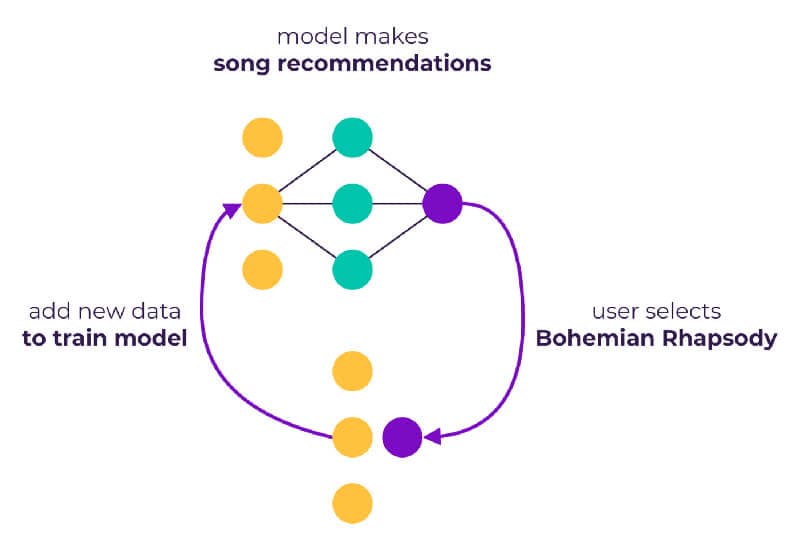
The model becomes more confident in a bad prediction and therefore keeps predicting with similar behavior instead of searching for better song choices. This is an example of verification bias.
Often the go-to solution is to involve direct user feedback, but this alone is not enough, as it, too, often leads to feedback loops.
The correct way is to use an algorithm that explores new solutions and exploits existing solutions. Such algorithms search for new solutions by trialing outputs that it typically would not, then adjusting its behavior based on user feedback. This allows the classifier to land on the optimal solution, and avoid the degrading feedback loop. The most common class of algorithms that balance exploration with exploitation are called bandit algorithms.
More dangerous still is the hidden feedback loop. These are related to direct feedback loops, except the feedback is generally many steps removed or the feedback happens indirectly, often in unintuitive ways.
Imagine there’s an ML algorithm (Ma) that does a good job predicting where crimes will occur. Then there’s another model (Mb), which determines where to optimally deploy police officers. Mb deploys more police officers to the area identified by Ma. Because of the increased number of officers, more crimes are uncovered. This indirectly validates Ma’s predictions, resulting in an indirect self-reinforcing hidden loop. We can see in this case that if hidden feedback loops aren’t properly accounted for it could lead to confirmation bias, and reinforce systematic discrimination against certain demographics and neighborhoods.
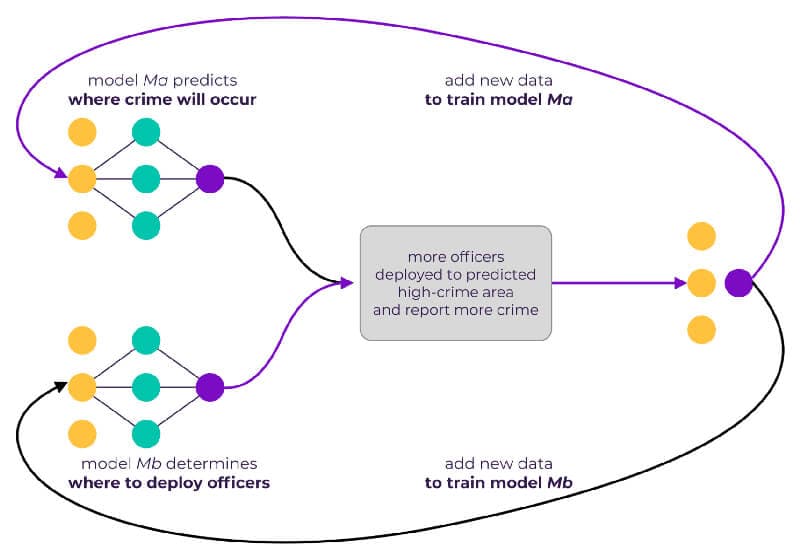
Hidden feedback loops are particularly difficult to detect. However, they can be mitigated by adding a certain amount of noise or variability in outputs, and also by using contextual bandit-like algorithms.
Ensuring your input data is stable, relevant, and not the ongoing product of a feedback loop will go a long way to ensuring your model is highly optimized and make it easier to identify and address issues in your model’s output.
The next post in this series explores what makes up the vast majority of any ML system: the plumbing code that handles the nitty gritty, the configuration, feature extraction, monitoring, and so on. All too often overlooked, it is essential to ensure that this code is managed in such a way as to allow your system to remain agile.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.