Data programming is a powerful and flexible tool that makes it easy to produce high quality labeled data for your specific use case with minimum effort.
Below, we walk you through:
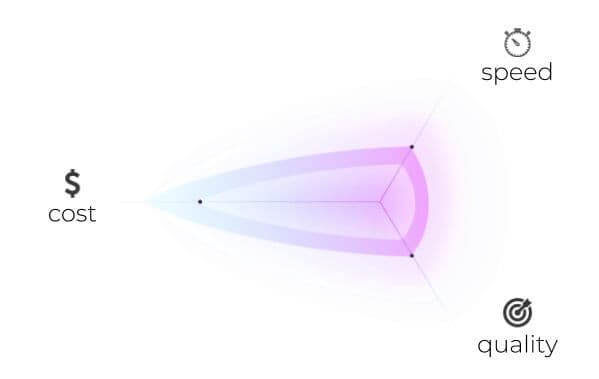
The definition of good labeled data depends upon the project type to which it applies. However, any description is ultimately a tradeoff between the following 3 factors:
Quality
Cost
Speed
Your project’s requirements determine which of these three are the most important and which can be cut back on. For example, labeled data used in an app for identifying products probably doesn’t need to be as high quality as that used in medical diagnoses, but it probably needs to be faster and cheaper. The relationship between the 3 variables is complex, but super.AI automatically calculates things for you based on your demands.
All three of these variables are powered by the same thing: labeling sources.
Improving quality means finding better labelers or a higher number of labelers of the same quality. Likewise, any improvement in speed comes from faster labelers or additional labelers for simultaneous labeling. Furthermore, cost is brought down by cheaper labelers.
For our enterprise clients, we can also use AI at times to dramatically drive down costs and improve speed while at the very least maintaining quality levels. We do this through the use of a meta AI, which forms part of the AI compiler.

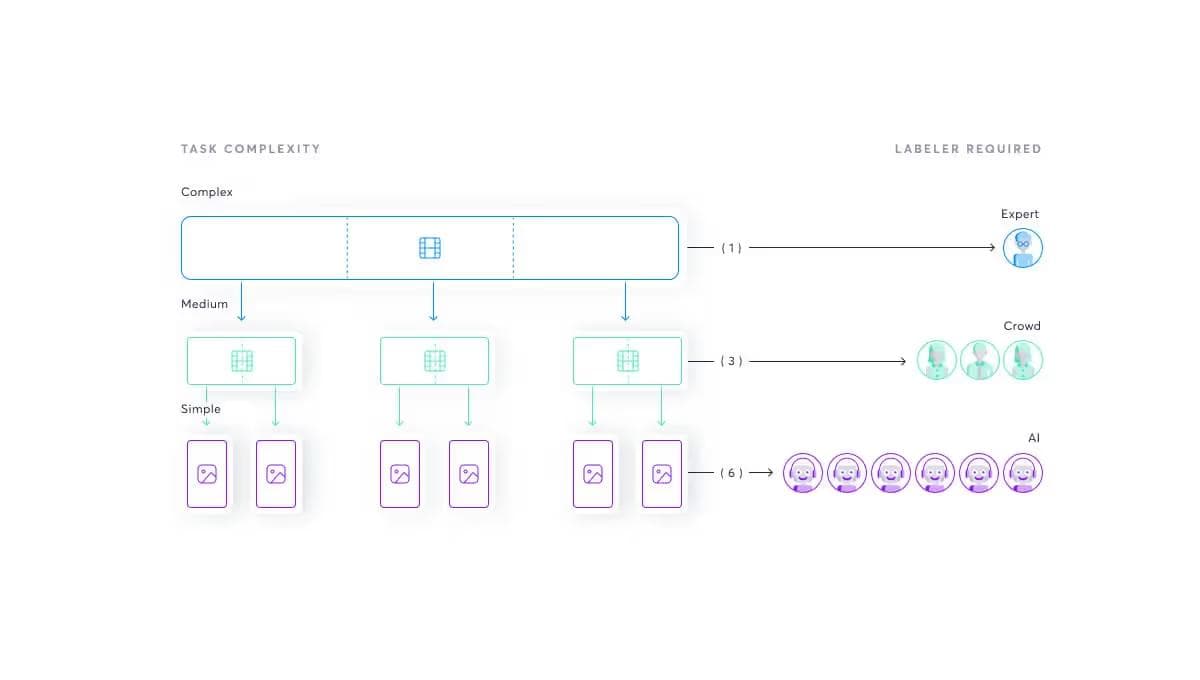
The complexity of many labeling tasks makes risks making them prohibitively expensive and error prone. Our realization was that data programming has to work like the assembly lines that revolutionised the manufacturing industry. This allows us to make data labeling—and therefore AI—affordable and accessible.
We built the super.AI system to break down complex tasks into smaller, simpler tasks. These tasks require less skill to complete, leading to lower costs. As we continue to simplify the tasks, we get to the point where there’s the potential to process the data using AI, further decreasing costs.
Saves on cost
Increases quality
Scalable
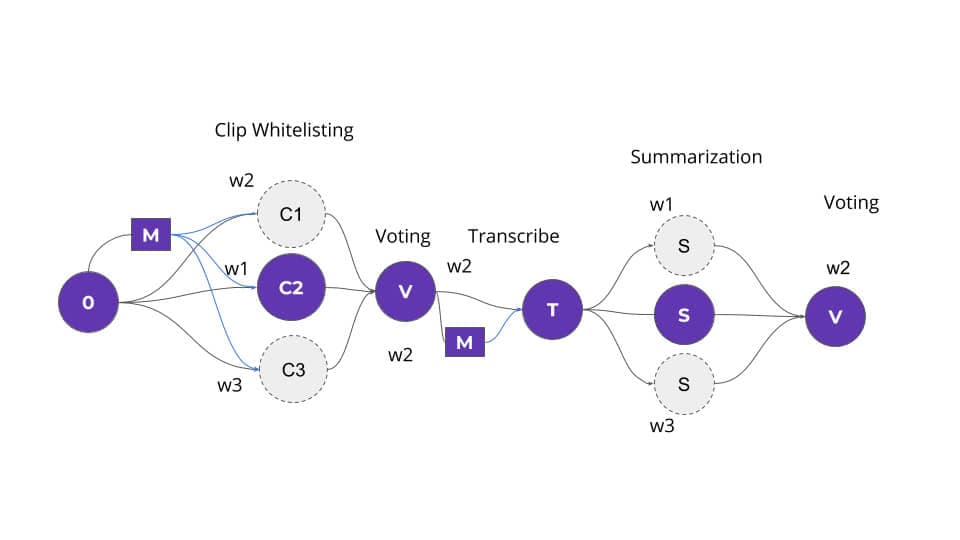
We’ve helped companies to automate key processes and build new products on the back of our data labeling. Here's one to give you a taste of how we can help.
LogMeIn used super.AI to power an AI bot that sits in on meetings and provides a summary that includes action items, takeaways, and overall sentiment.
We took LogMeIn’s raw audio and processed it in the following steps:



Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.