By David Roberts

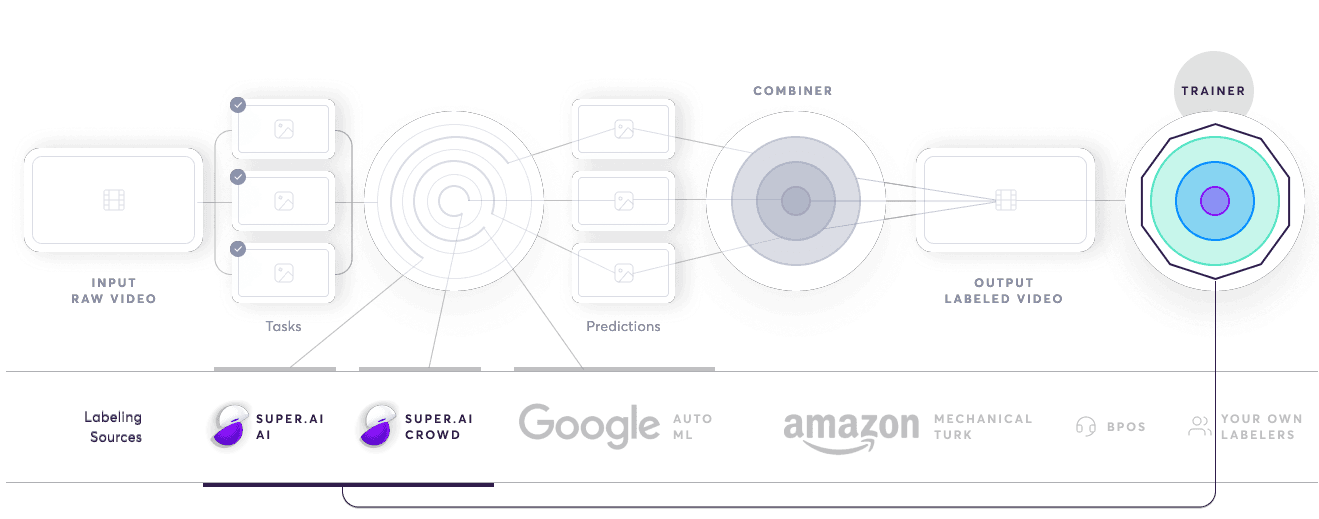
The AI compiler is the execution system for the super.AI assembly line described in our Data programming post. It ensures that all inputs are split into smaller tasks that are efficiently and accurately labeled before being recombined into a coherent output. The AI compiler also uses the processed outputs it receives as training data for machine learning algorithms that go on to form an additional labeling source. Below, we’ll take a look at each stage of the AI compiler in detail.
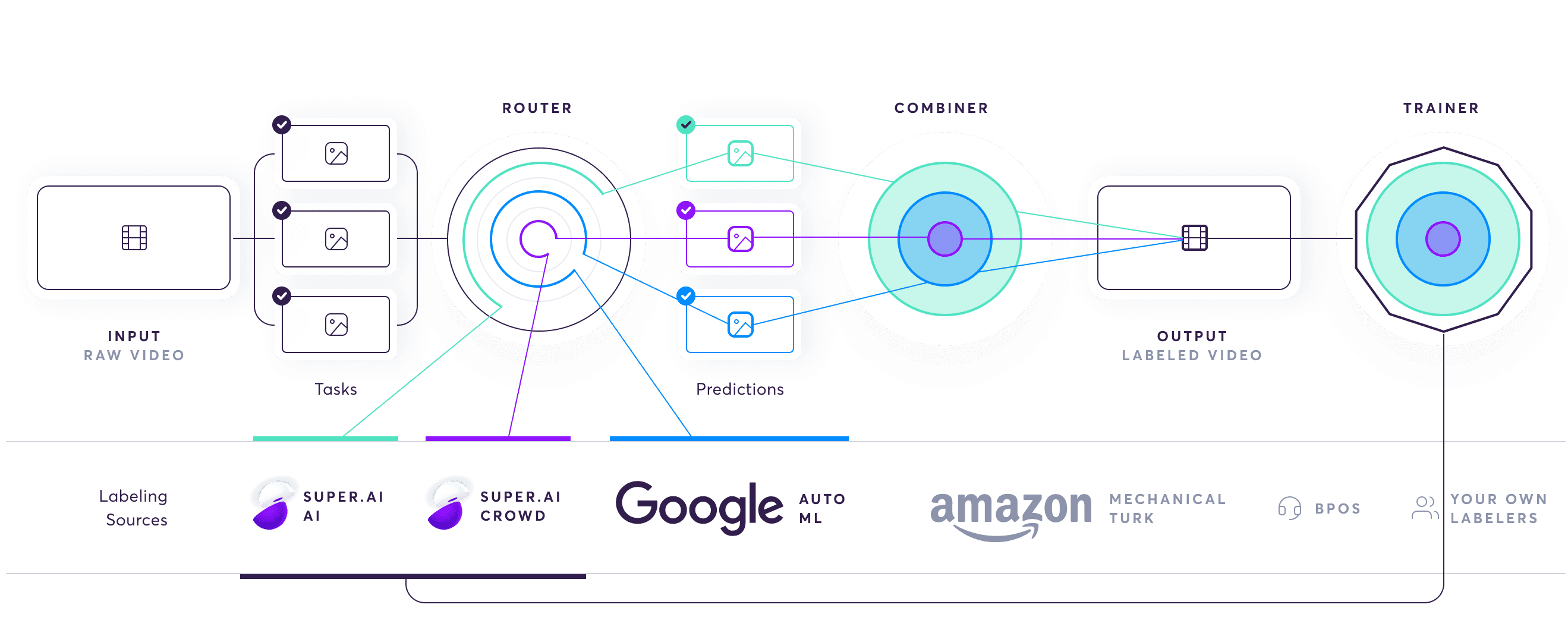
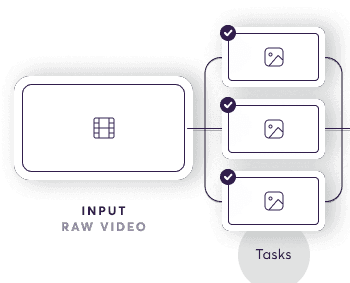
Things start on the left of the diagram above, with the input of raw data. The AI compiler’s first task is to separate a single input into smaller pieces or tasks. Each data point has to be treated differently. This is a unique challenge and inevitably where the reality diverges from the assembly line analogy. For example, simple image inputs can vary wildly in terms of how noisy they are, so we have to handle each accordingly.
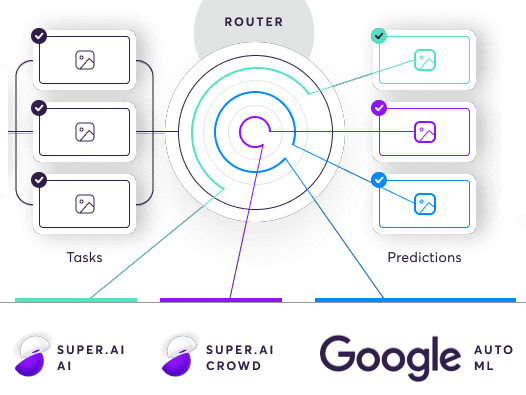
Once we’ve divided the input data into discrete tasks, the AI compiler sends them to the router. The router sits over a database of labeling sources. Labelers are a mix of humans and machines, including AI and software functions, such as Snorkel. Each labeling source has 3 distributions (quality, cost, and speed). Based on these, the router decides, according to the project’s requirements, which labeling sources are best to handle the task and sends it there for labeling. The router can choose to use multiple sources for a single task, be that multiple people, multiple machines, or a combination of both.
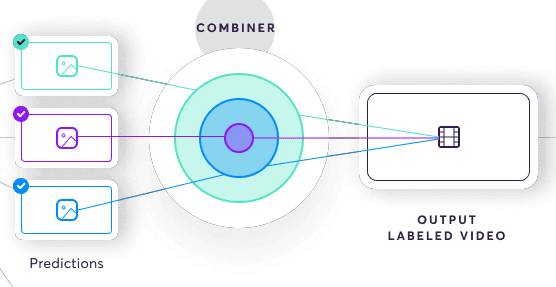
Once all the labeling sources have completed a task, the combiner produces an importance-weighted combination of them as the final output. This is one of the most complex parts of the system. It uses a generative model to intelligently determine the most accurate output by answering questions such as how many non-skilled labelers it takes to outweigh a single expert labeler.
The trainer module functions as a meta AI that uses outputs from the combiner as training data for machine learning models. Once a model reaches a certain level of quality, the trainer adds them to the labeling sources database, making them accessible to the router described in step 2. As more data gets labeled within a project, the models produced by the meta AI improve in quality and the router can rely on them more as a labeling source. The result: costs go down dramatically and the labeling process speeds up without affecting the quality guarantee.
The trainer module is also responsible for automatically training human labelers. It takes the labeled output it receives and feeds it into the super.AI labeler qualification system. In addition, the trainer helps to regulate payment for tasks and keep labelers motivated.
Every subsystem within the AI compiler has trainable parameters. super.AI uses reinforcement learning (specifically a partially observable Markov decision process, or POMDP) to update these parameters. This allows the AI compiler to, e.g., remove a poor labeling source from its database and adjust the task distribution to the other labeling sources accordingly. Through this, we not only achieve higher quality, but also faster, cheaper, and more scalable results.
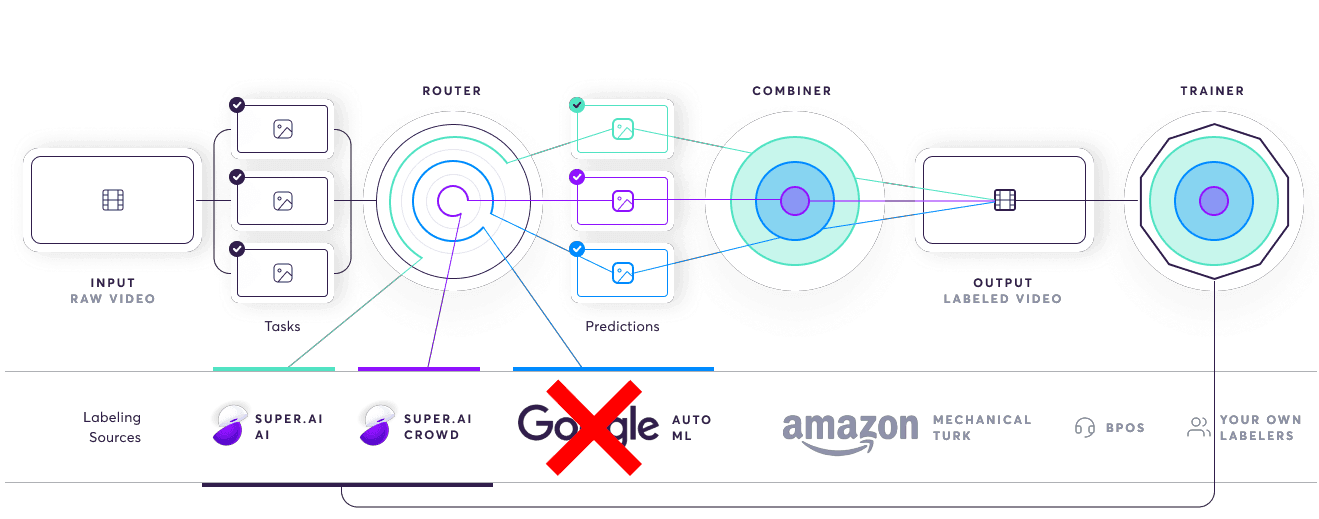
Some of the AI-enabled features of the AI compiler, such as the meta AI and some of the measurement and QA systems are only available to enterprise clients. To learn more, talk to our sales department.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.