By David Roberts
Super.AI makes use of over 150 methods of quality assurance (QA). In this blog post, we’re going to take a look at the main techniques to understand better how the complex process of unstructured data processing can come with a quality guarantee. Some of our quality assurance methods are only available to our enterprise clients. To find out more, contact us.

There are four primary areas under which our quality assurance takes place:
Human labelers are an essential component of getting difficult data labeled well. Super.AI has its own first-party crowd for exactly this reason. We work hard to ensure that all our labelers meet a minimum bar for entry into our system and after that create a hierarchy of labeler ability. We continually conduct assessments to measure consistency and focus, while providing incentives and reward for our labelers.
Before a labeler conducts any labeling in a production system, we need to measure their quality so that this information can be fed to the router, which decides if and when to send labeling tasks to the labeler.
We conduct labeler qualification in 3 ways:
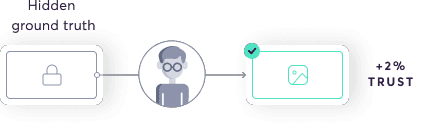
We intermittently audit labelers by sending them tasks where we know the correct answers. By comparing their output to the ground truth output, super.AI is able to update the quality distribution for the labeler.
Occasionally, there will be subjective tasks. We try to avoid this, but it’s not always possible. In this case, the task will have to be graded by a trusted—most likely human—source.
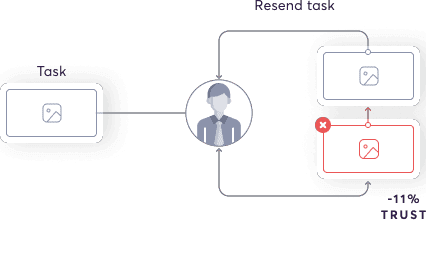
We measure labeler fatigue by feeding labelers tasks that are similar to a previous task but with subtle differences. By comparing the two answers, we can update the quality distribution for the labeler. This is an unsupervised process—unlike qualification and ground truth—so we can use any data, even where we don’t know the correct output.

The rewards our labelers receive are tied to the value they produce. We actively and adaptively encourage high performance through a reward-based system, which includes gamification features.
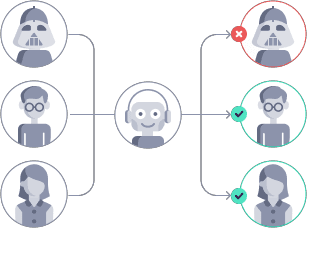
After the qualification process and once we’re running consistency checks and conducting ongoing quality control, super.AI can determine the ideal attributes for a labeler on a specific project. Based on this, we can remove labelers that lack these attributes. While this system is not perfect, it has the potential to greatly increase quality when used with its limits in mind.
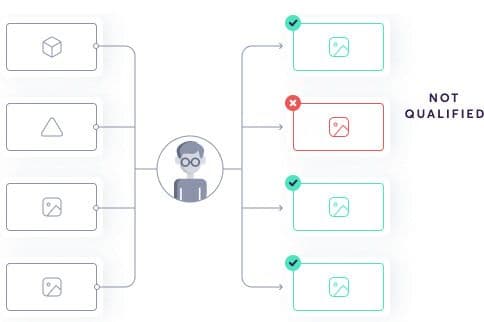
Super.AI deals with a huge variety of task types. We’ve developed a set of checks to apply across the board to maximize task quality.
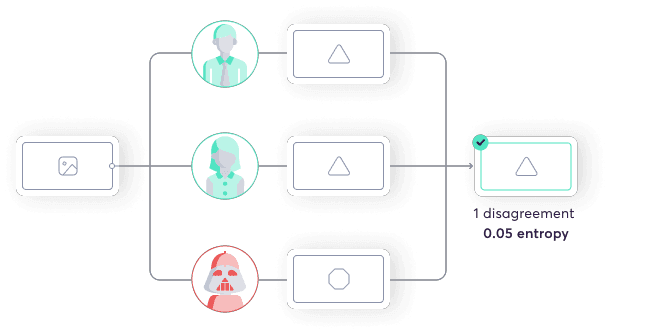
Super.AI can route tasks to multiple labelers and take the consensus output. The combiner does this using a generative model. Increasing quality requires you to measure the quality of each individual labeler as well as the overall number of labelers, but you also need to measure the correlation between your labelers. If a set of labelers is likely to produce the same answer, there’s no need to send them the same task. The combiner and consensus system work to group labelers that do not produce similar answers, i.e., uncorrelated labelers.
Not all data points are created equal. Difficulty varies, so we have to treat each differently. Generally we submit a new data point to a single labeling source, then determine the quality of the output. If it’s not high enough, we can improve it by adding more (uncorrelated) labelers. So a simple data point might have just 1 labeler, while a more complex one might have 10.

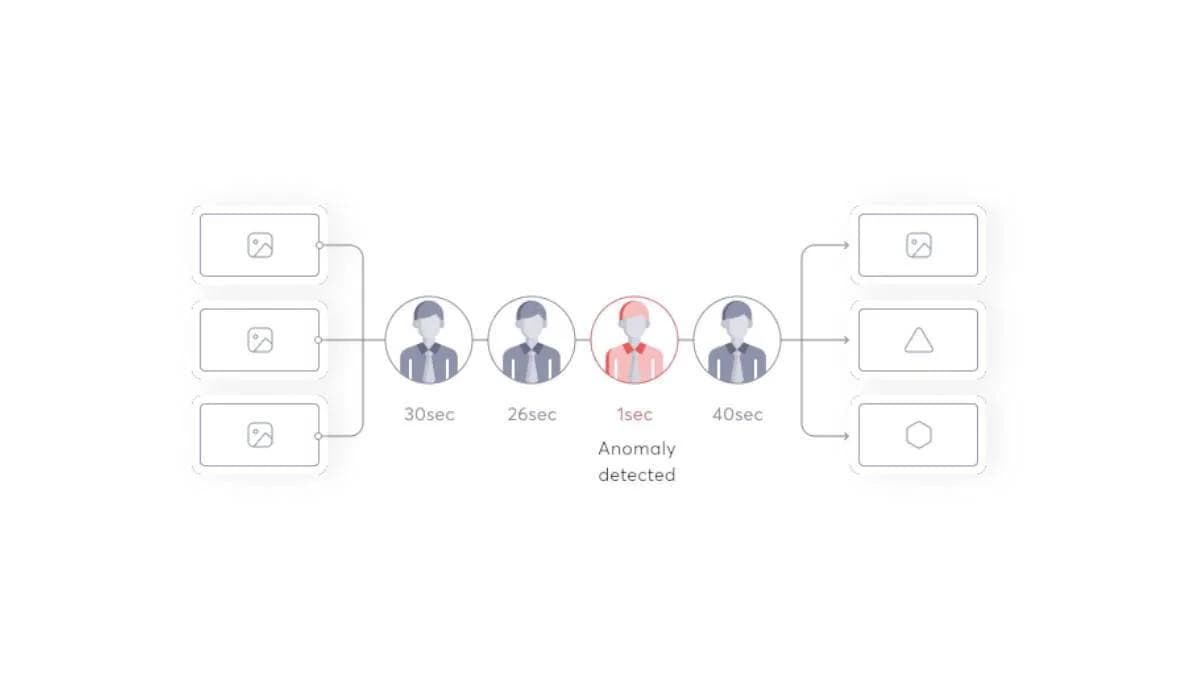
Certain actions can give signals about quality, e.g., how long a labeler takes to complete a task. If someone spends an unusually long or short time on a task, this triggers the anomaly detector, and we can conduct a review (see below). Anomalies are an indicator that a task might not be high quality.
Super.AI has a group of in-house expert labelers. They work on any ground truth that requires a subjective assessment (see the ground truth section above) and on general tasks determined by a partially observable Markov decision process (POMDP).
If you prefer, you can also integrate your own reviewers into the system.
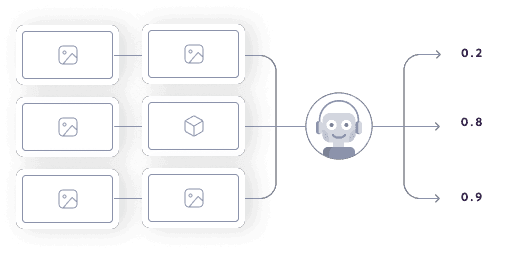
Similar to how the anomaly detector can identify unusual actions, the ML likelihood classifier learns a distribution within which you’d expect the output to fall. So, for example, if the ML likelihood classifier spots an unusually large or small bounding box on a task, it will flag the output for review.
Sometimes your data will be processed by humans and other times by AI. When it’s humans doing the processing, we need clear, concise text instructions describing how to effectively execute your task. We've devised a series of tests to ensure instructions are as useful for our human labelers as possible.
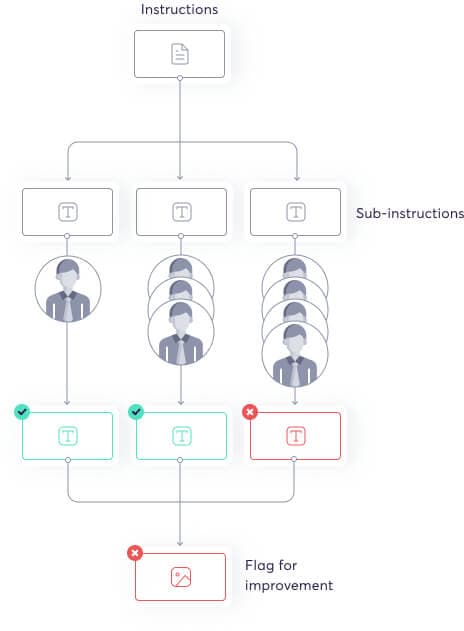
This is a sort of meta data program that super.AI uses to assess the quality of custom instruction sets. It breaks the instruction set down into smaller chunks and conducts an assessment to determine quality and identify problems.
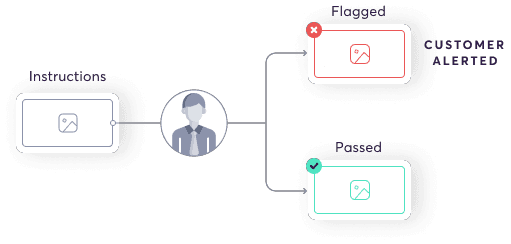
For enterprise clients, we offer an internal team of auditors to assess instructional quality and validity, guaranteeing a superior level of quality.
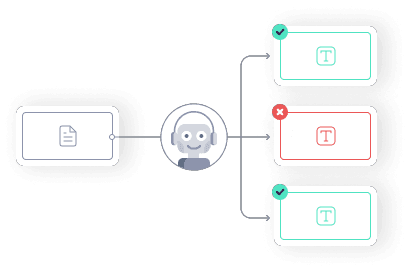
Super.AI trains an NLP model on the successful instructions that our users input into their data programs. This model can assess the semantic and syntactic validity of instruction sets automatically and flag common errors for correction.
All of the above measures will ultimately be for little if the input data itself is poor quality. It’s an essential step for super.AI to conduct exhaustive checks on data quality.
The data linter provides automatic detection of common errors and suggests improvements. We use off-the-shelf software with a proven track record to do this.
Noise models allow us to look at the signal-to-noise ratio of input data and flag any data points with an unusually low ratio. This assessment is especially important for unstructured data.
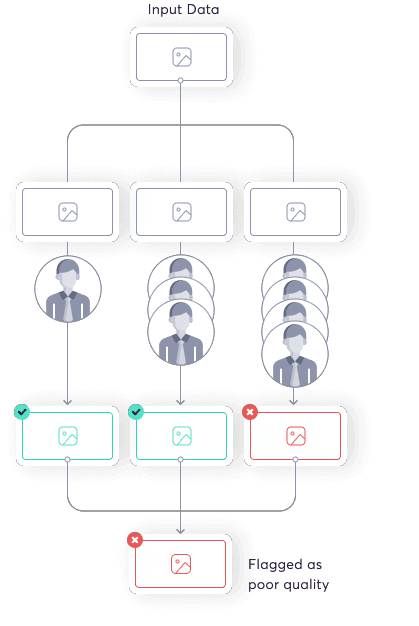
We process input data using our own in-house master quality data program. This data program breaks the input data into chunks that are sent to labelers, who assess the quality. If the data proves not to be high enough quality, it is flagged and the user is notified that their data might produce poor results.
The quality of input data is not always self apparent, so this forms an important validation step.


Most invoice problems aren't processing problems — they're capture problems. Learn what invoice data capture is, where it breaks down, and how AI fixes it.

Manual document processing costs more than most teams realize. Learn what document process automation is, how it works, and what to look for in a platform.